Khi xây dựng các mô hình AI hoặc LLM, thu thập dữ liệu web quy mô lớn (web extraction) là bước nền tảng sống còn của các Data Engineer và Machine Learning Engineer. Tuy nhiên, nếu bạn chỉ sử dụng các thư viện HTTP cơ bản bằng Python kết hợp với một vài dải IP tĩnh, hệ thống của bạn sẽ nhanh chóng ngập trong các thông báo như các mã lỗi Proxy phổ biến bao gồm 403 Forbidden và 429 Too Many Requests.
Bài viết này sẽ mổ xẻ nguyên lý hoạt động của các hệ thống bảo mật hiện đại, giải mã các dấu vân tay bảo mật mạng, và hướng dẫn thiết lập kiến trúc proxy dân cư thu thập dữ liệu kết hợp cùng Scrapy để tối ưu hóa quá trình trích xuất thông tin ở quy mô triệu trang mà vẫn tuân thủ các chuẩn mực đạo đức.
Nỗi ám ảnh của Data Engineer: Dấu vân tay mã hóa và hệ thống Anti-Bot
Việc đổi IP liên tục là không đủ để đáp ứng các tường lửa bảo mật hiện đại. Các hệ thống này không chỉ nhìn vào địa chỉ IP mà còn soi xét cực kỳ chi tiết vào cấu trúc gói tin mạng của bạn. Nhiều kỹ sư đã phải đau đầu tìm hiểu tại sao nên sử dụng kết hợp Proxy và VPN thay vì chỉ so sánh chúng để tìm ra giải pháp tối ưu nhất.
Khái niệm JA3 và HTTP2 Fingerprint
- JA3 Fingerprint: Đây là một tiêu chuẩn tạo dấu vân tay cho ứng dụng client thông qua giao thức SSL/TLS. Khi bắt đầu một phiên TLS, client gửi một gói tin TLS Client Hello. Kỹ thuật JA3 sẽ thu thập giá trị thập phân của các byte từ 5 trường trong gói tin này bao gồm: Phiên bản SSL (Version), Các bộ mã hóa được chấp nhận (Accepted Ciphers), Danh sách tiện ích mở rộng (List of Extensions), Elliptic Curves, và Elliptic Curve Formats. Các giá trị này được nối lại và băm bằng thuật toán MD5 để tạo ra một chuỗi 32 ký tự nhận diện chính xác client (Chrome, Safari hay một script mạng).
- HTTP2 Fingerprint: Tương tự JA3, các hệ thống bảo mật (như Cloudflare) duy trì một cơ sở dữ liệu về dấu vân tay HTTP/2 hợp lệ. Khi một dấu vân tay HTTP/2 mới hoặc bất thường xuất hiện đồng loạt, nó sẽ lập tức bị nhận diện là mạng botnet.
Tại sao script Python thuần túy lại dễ dàng bị phát hiện?
Khi dùng các thư viện Python thuần túy như requests hay httpx, scraper của bạn dễ dàng bị chặn bởi:
- Lộ dấu vân tay TLS/JA3 và HTTP/2: Các thư viện này không tự động mô phỏng (impersonate) được dấu vân tay của trình duyệt thực tế.
- Sử dụng HTTP/1.1: Hầu hết trình duyệt hiện nay mặc định giao tiếp bằng HTTP/2, trong khi nhiều script Python vẫn gửi request bằng HTTP/1.1. Đây là tín hiệu rõ ràng để WAF chặn request.
- Bất đồng bộ Header và Fingerprint: Nhiều người cố cấu hình User-Agent thành Chrome. Tuy nhiên, nếu bạn khai báo là Chrome nhưng dấu vân tay TLS lại là của Python, hệ thống sẽ phát hiện sự mâu thuẫn và chặn ngay lập tức.
Các thư viện Python thuần túy không tự động mô phỏng (impersonate) được dấu vân tay của trình duyệt. Thậm chí, việc tự động hóa Proxy Rotation bằng Python (2026) nếu không đi kèm khả năng mô phỏng vân tay TLS vẫn sẽ khiến hệ thống thu thập dữ liệu của bạn bị chặn ngay lập tức.
Các lá chắn Anti-Bot hàng đầu hiện nay
- Cloudflare (Bot Management / Turnstile): Kiểm tra gắt gao dấu vân tay TLS (băm JA3, JA4, HTTP/2), kết hợp vân tay JavaScript, danh tiếng IP và chấm điểm tin cậy qua Turnstile CAPTCHA.
- Akamai & Kasada: Đánh giá nghiêm ngặt vân tay TLS, yêu cầu scraper phải vượt qua các điểm kiểm tra API để lấy được các token hợp lệ.
- DataDome & Incapsula (Imperva): Giám sát TLS, theo dõi cookie, header và hành vi người dùng để phân loại bot.
- PerimeterX: Dùng cơ chế phát hiện tự động hóa kết hợp các dấu hiệu tĩnh và dấu hiệu mạng để chặn truy cập phi con người.
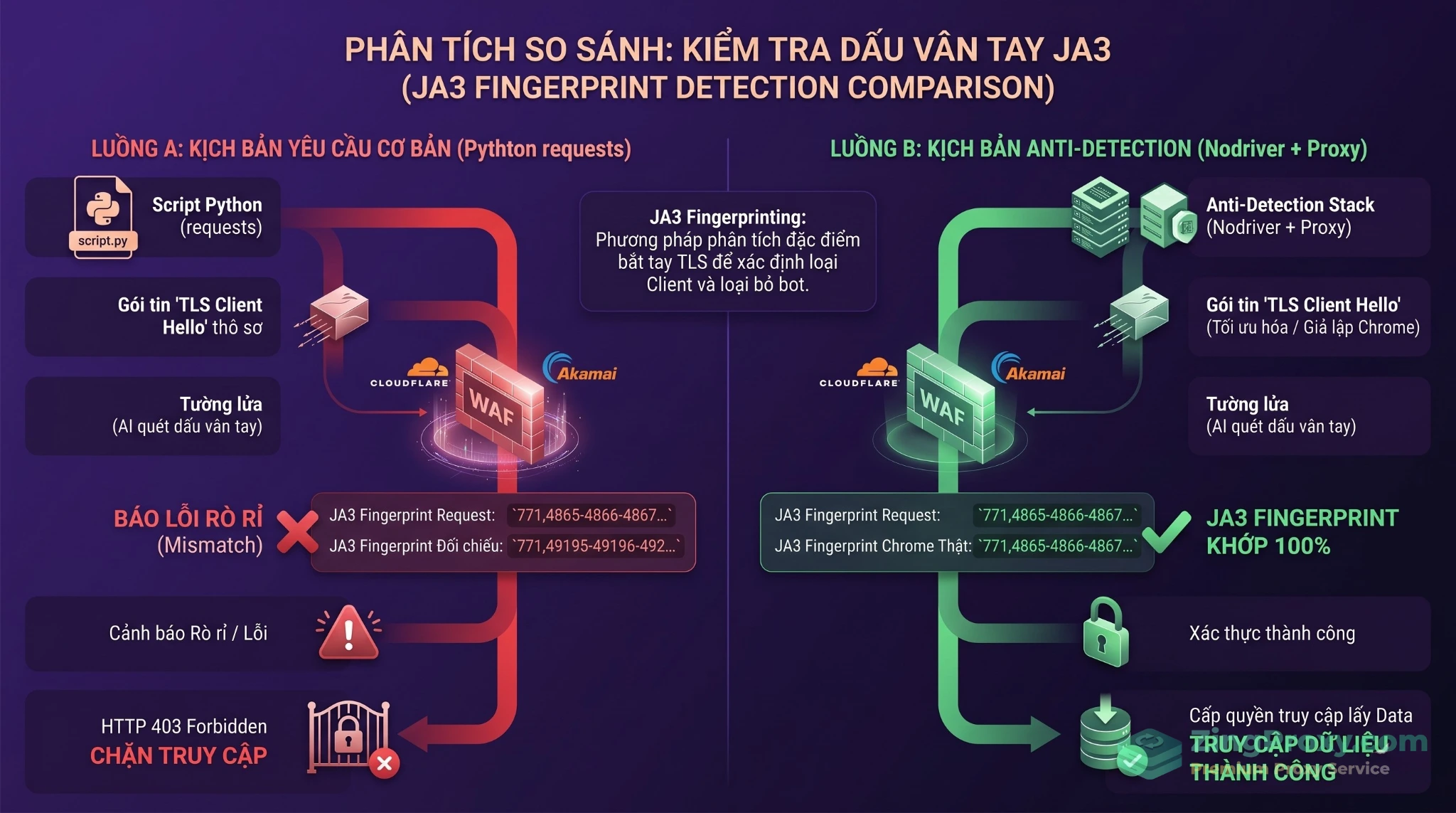
Cơ chế phát hiện bot dựa trên dấu vân tay TLS/JA3 và sự khác biệt giữa Python thuần túy so với hệ thống mô phỏng trình duyệt.
Hệ thống mô phỏng trình duyệt: Xử lý kết nối ở quy mô lớn
Để tương thích với các hệ thống trên, các công cụ tự động hóa tiêu chuẩn như Puppeteer, Playwright hay Selenium mặc định là chưa đủ, bạn cần thiết lập một Hệ thống mô phỏng trình duyệt (Browser Emulation Stack). Các kỹ sư thường chọn giải pháp dựng hệ thống Proxy doanh nghiệp Geo-Testing chuẩn xác với Playwright (2026) để mô phỏng chính xác hành vi người dùng thực. Ngoài ra, các công cụ tự động hóa chuyên sâu như Nodriver hay SeleniumBase UC Mode là những trợ thủ đắc lực trong năm 2026:
- Nodriver (Khuyến nghị cho 2026): Sử dụng giao thức Direct Chrome DevTools để giao tiếp với Chrome, vá lỗi ở cấp độ driver. Kết hợp Nodriver với proxy dân cư thu thập dữ liệu được xem là phương pháp toàn diện nhất hiện nay.
- SeleniumBase UC Mode: Tự động vá dấu vân tay bị lộ, ngăn rò rỉ giao thức CDP và xử lý tốt Turnstile CAPTCHA.
- Camoufox: Xây dựng trên lõi Firefox với hồ sơ người dùng thật, giúp giảm thiểu rủi ro bị chặn bởi các hệ thống giám sát trình duyệt Chromium.
- curl_cffi / curl-impersonate: Sao chép chính xác chữ ký TLS và header HTTP cho các tác vụ không cần kết xuất HTML (render JS).
Chiến lược Proxy: Residential Proxy vs Mobile Proxy (CGNAT)
Tùy vào quy mô dữ liệu, bạn cần có chiến lược phân bổ proxy tối ưu chi phí.
Residential Proxies (proxy dân cư) tiêu chuẩn vàng
Proxy dân cư thu thập dữ liệu là tiêu chuẩn vàng cho việc trích xuất dữ liệu có khả năng mở rộng (scalable data collection). Với mạng lưới hàng triệu IP thực từ hộ gia đình và giá thành tính theo GB hợp lý, đây là lựa chọn hoàn hảo nhất cho việc xây dựng dataset LLM, e-commerce hay travel, đảm bảo tỷ lệ thành công 95-99%.
Mobile Proxies và sức mạnh của CGNAT
Dù đắt đỏ, Mobile Proxy là giải pháp bảo đảm kết nối mạnh mẽ nhất nhờ cơ chế CGNAT (Carrier-Grade NAT RFC 6598):
- Lá chắn từ người dùng thật: Hàng ngàn người dùng 4G/5G chia sẻ chung 1 IP public. Hệ thống bảo mật hạn chế chặn IP này vì nguy cơ ảnh hưởng đến hàng ngàn khách hàng thật của nhà mạng.
- Lưu lượng không thể phân biệt: Request của bạn hòa vào biển lưu lượng thiết bị di động, trông hoàn toàn tự nhiên.
- Luân chuyển IP tự nhiên (Natural Rotation): Nhà mạng liên tục làm mới pool IP. Một modem có thể tiếp cận hơn 100.000 IP mà không lo bị suy giảm chất lượng IP (No Pool Degradation).
Chiến lược thực chiến: Hãy dùng cấu trúc Hybrid (Kết hợp). Dùng proxy Datacenter cho trang không giới hạn, ưu tiên Residential Proxy cho data pipeline quy mô lớn, và chỉ dùng Mobile Proxy cho các hệ thống có tiêu chuẩn bảo mật khắt khe.
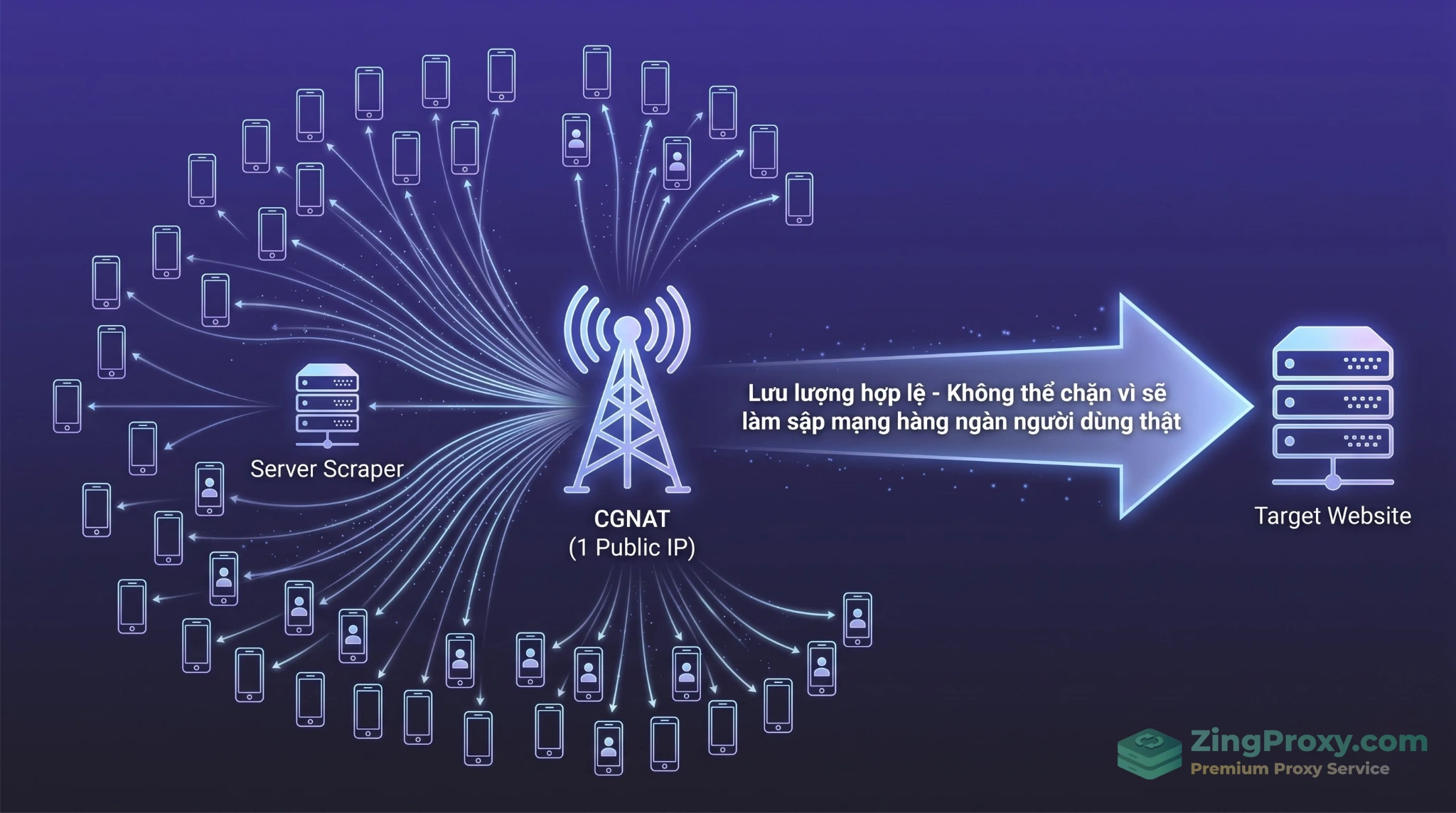
Cơ chế CGNAT giúp request của hệ thống hòa lẫn vào biển lưu lượng của hàng ngàn thiết bị di động, tạo ra mức độ uy tín cấp độ nhà mạng.
Kiến trúc Scrapy bất đồng bộ và quản lý Concurrency
Scrapy là framework mạnh mẽ nhất để xử lý hàng triệu trang nhờ kiến trúc bất đồng bộ. Luồng request đi qua một pipeline chặt chẽ:
Spider -> Spider Middleware -> Scheduler -> Downloader Middleware -> Downloader -> Spider
Trong đó, Downloader Middleware là chốt chặn quan trọng nhất để tích hợp logic luân chuyển proxy (proxy rotation) trước khi request chạm đích. Tuy nhiên, sai lầm chí mạng của nhiều kỹ sư là thiết lập số lượng kết nối đồng thời (Concurrency) sai lệch.
Để xử lý triệt để bài toán hiệu năng, bạn nên tham khảo kiến trúc tích hợp Proxy Pool vào Kubernetes Cluster (2026).
Nguyên tắc vàng về Concurrency:
Thông số CONCURRENT_REQUESTS chỉ nên được đặt ở mức gấp 3 đến 5 lần số lượng cổng proxy.
- Cảnh báo: Nếu bạn có 3 cổng Mobile Proxy nhưng đẩy 50 request đồng thời, mỗi cổng sẽ gánh 17 kết nối cùng lúc. Việc một thiết bị di động mở hàng chục kết nối đồng thời là hành vi cực kỳ thiếu tự nhiên, lập tức kích hoạt giới hạn tốc độ (rate limits) và bị chặn. Giới hạn an toàn trong trường hợp này chỉ là 9 đến 15 request.
Thu thập dữ liệu đạo đức: Hiểu mã 429 và Robots.txt
Giải mã HTTP 429 (Too Many Requests)
Mã HTTP 429 báo hiệu client đã gửi quá nhiều yêu cầu vượt mức giới hạn. Khi gặp lỗi này, hệ thống của bạn bắt buộc phải:
- Kích hoạt thuật toán lùi thời gian thích ứng (Adaptive Back-off) để làm chậm tốc độ gửi request.
- Đọc header
Retry-After để tuân thủ thời gian chờ hệ thống yêu cầu.
- Áp dụng Circuit Breaker (Ngắt mạch) để ngưng gửi request ngay lập tức, tránh gây quá tải thêm cho máy chủ.
Điều này không chỉ giúp bảo vệ máy chủ đích mà còn là nền tảng để tối ưu hạ tầng AI Agent thông qua việc phân tải request mượt mà bằng Proxy dân cư xoay vòng (2026) một cách bền vững.
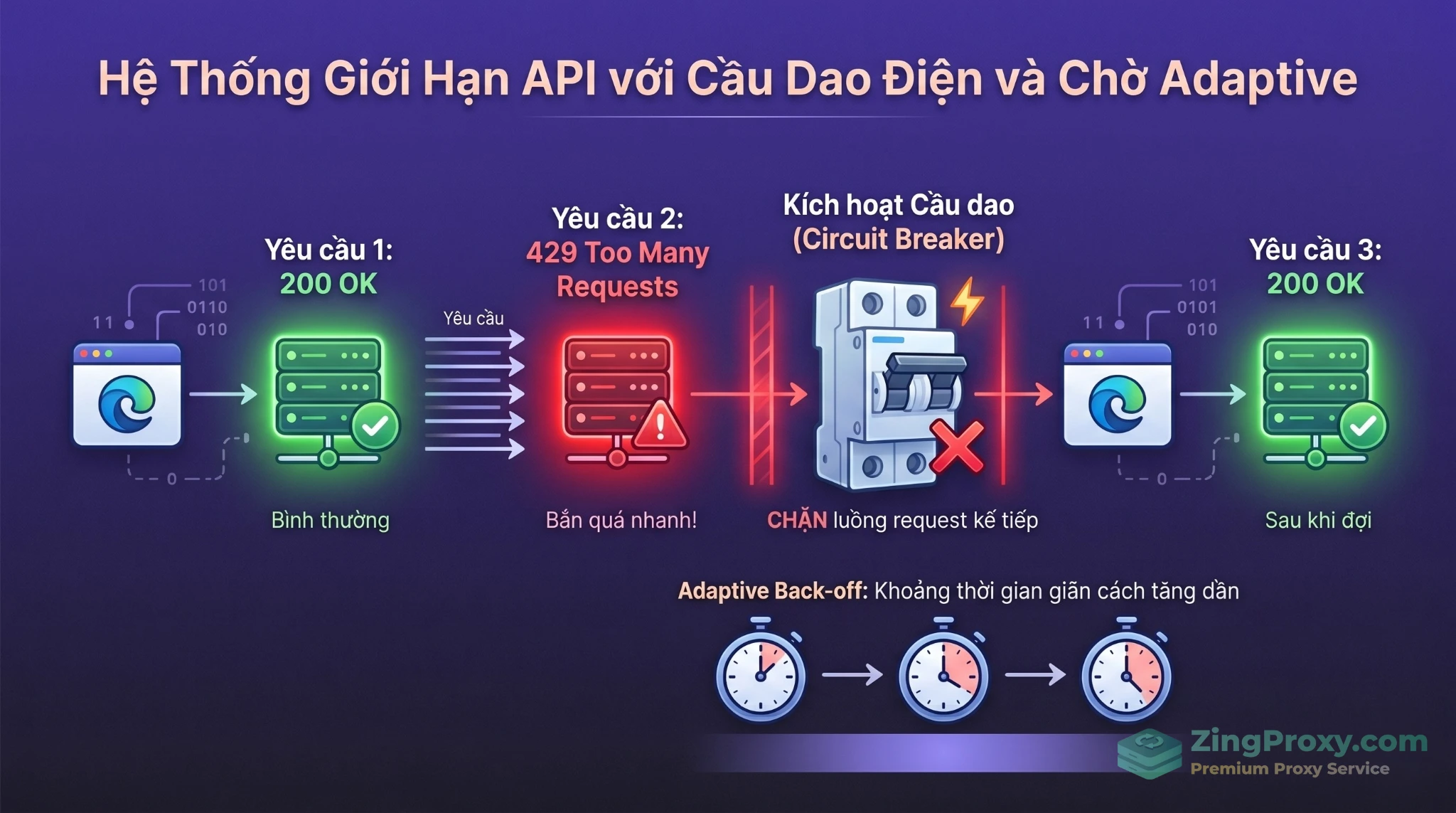
Áp dụng cơ chế Ngắt mạch (Circuit Breaker) và Lùi thời gian thích ứng (Adaptive Back-off) để xử lý triệt để mã lỗi 429.
Sự thật về Robots.txt và chỉ thị Crawl-delay
Theo chuẩn RFC 9309, tệp robots.txt dùng để chỉ dẫn bot những URL được/không được phép truy cập. Nó không phải là công cụ bảo mật (nếu muốn ẩn trang, bạn phải dùng thẻ noindex hoặc yêu cầu xác thực).
Đáng chú ý, Crawl-delay là một chỉ thị không chính thức.
- Googlebot bỏ qua hoàn toàn chỉ thị này và tự điều chỉnh tốc độ dựa trên thời gian phản hồi máy chủ.
- Bing xử lý theo dạng cửa sổ thời gian, trong khi Yandex tính bằng số giây chờ tối thiểu.
Thay vì trông cậy vào Crawl-delay, cách bảo vệ máy chủ chuẩn xác nhất là cấu hình trả về HTTP 503 (Service Unavailable) hoặc HTTP 429, kết hợp với việc kiểm soát tốc độ qua Google Search Console.
Câu hỏi thường gặp (FAQ)
1. Proxy dân cư (Residential Proxy) khác gì Proxy Datacenter?
Proxy dân cư dùng IP của mạng wifi gia đình thực tế (độ uy tín cao, giá thành phù hợp chất lượng, tỷ lệ hoạt động ổn định 99%). Proxy Datacenter dùng IP của máy chủ ảo đám mây (giá rẻ, tốc độ cao nhưng dễ bị tường lửa chặn do không chia sẻ IP với người dùng thực).
2. Tại sao tôi đổi IP liên tục bằng Python requests nhưng vẫn bị Cloudflare chặn?
Do hệ thống của bạn bị lộ dấu vân tay mã hóa (TLS/JA3 Fingerprint). Đổi IP chỉ che giấu địa chỉ, nhưng cấu trúc gói tin TLS vẫn phản ánh bạn đang sử dụng một script Python chứ không phải trình duyệt Chrome tiêu chuẩn.
3. Cơ chế CGNAT của Mobile Proxy hoạt động hiệu quả ra sao?
Là kiến trúc mạng lưới nơi nhà cung cấp chia sẻ 1 IP 4G/5G cho hàng ngàn điện thoại cùng lúc. Hệ thống bảo mật hạn chế chặn dải IP này nhằm tránh rủi ro chặn nhầm hàng ngàn khách hàng thật đang lướt web hợp lệ.
4. Nên thiết lập số request đồng thời (Concurrency) trong Scrapy là bao nhiêu?
Quy tắc nền tảng: Gấp 3 đến 5 lần số lượng cổng (port) proxy của bạn. Có 3 cổng proxy thì chỉ nên chạy 9 đến 15 request đồng thời để tránh tạo ra lưu lượng truy cập bất thường.
5. Gặp mã lỗi HTTP 429 thì hệ thống phải xử lý như thế nào?
Mã 429 biểu thị trạng thái gửi quá nhiều yêu cầu đến server. Bạn cần lập tức ngắt mạch (Circuit Breaker) và áp dụng độ trễ tăng dần (Adaptive Back-off) trước khi thử kết nối lại.
6. Có nên dùng lệnh Crawl-delay trong file robots.txt để giới hạn tốc độ thu thập dữ liệu không?
Không. Đây là lệnh không chính thức. Các hệ thống tiêu chuẩn như Googlebot bỏ qua hoàn toàn lệnh này. Để quản lý lưu lượng tối ưu, hãy cấu hình server trả về mã lỗi 503 hoặc 429 thay vì tin tưởng vào Crawl-delay.
Kết luận
Việc kết hợp giữa các thư viện tự động hóa cao cấp (như Nodriver), quản lý concurrency chuẩn xác trong kiến trúc bất đồng bộ của Scrapy và hệ thống proxy dân cư thu thập dữ liệu sẽ giúp bạn tạo ra một Data Pipeline bền bỉ. Đồng thời, hãy luôn xử lý mã lỗi 429 bằng cơ chế Back-off và Circuit Breaker để đảm bảo hạ tầng của bạn hoạt động như một hệ thống trích xuất dữ liệu tiêu chuẩn, tôn trọng tài nguyên máy chủ của cộng đồng web.
Tài liệu tham khảo