Bạn vừa gõ xong lệnh git push, pipeline CI/CD kích hoạt. Đáng lý ra chỉ khoảng 10 phút sau là team sẽ nhận được report review code và test case sinh tự động từ AI. Nhưng thực tế lại tàn nhẫn hơn nhiều: Cả team ngồi nhìn màn hình terminal tĩnh lặng ròng rã 40 phút. Hàng loạt request báo timeout, luồng stream phản hồi bị đứt gãy giữa chừng, và cuối cùng pipeline báo lỗi hệ thống.
Nhiều Developer hì hục tăng biến timeout trong code một cách vô vọng. Một số khác đổ lỗi cho nền tảng AI. Tuy nhiên, khi làm việc với một mô hình ngôn ngữ lớn (LLM) hạng nặng như Kimi K2.6, nguyên nhân gây sập hệ thống đến từ sự kết hợp của 2 nút thắt: Đặc tính suy luận sâu của Model và Băng thông mạng quốc tế chập chờn.
Giải pháp thực dụng nhất mà các Tech Lead đang áp dụng không phải là viết lại code, mà là can thiệp hạ tầng mạng: Thuê Proxy US kết hợp với cấu hình SDK chuẩn xác. Hãy cùng mổ xẻ nguyên nhân lỗi của Kimi K2.6 và cách khắc phục dứt điểm.
Nỗi đau timeout: Sự thật phũ phàng về hiệu năng của Kimi K2.6
Tích hợp AI Agent vào test code là để tăng tốc độ phát triển. Nhưng nếu bạn không hiểu rõ đặc tính của model, công cụ này sẽ lập tức phản tác dụng.
Mô hình siêu nặng: TTFT 3.04s và output 34 t/s
Nhiều QA Automation lầm tưởng có thể nhận được response tức thì. Thực tế, Kimi K2.6 là một mô hình MoE với năng lực reasoning (suy luận) cực sâu, do đó nó chậm hơn đáng kể so với mặt bằng chung các mô hình mã nguồn mở cùng kích cỡ:
- Chỉ số TTFT (Time to First Token): Đạt 3.04 giây (cao hơn mức trung vị 2.29s).
- Tốc độ sinh mã (Output Speed): Đạt 34.0 tokens/giây (thấp hơn nhiều so với mức trung vị 57.5 t/s).
Khi AI đã mất tới hơn 3 giây chỉ để xử lý ra ký tự đầu tiên, cộng thêm tốc độ nhả chữ chậm rãi, bạn không thể cho phép đường truyền mạng tốn thêm thời gian cho việc TCP Handshake qua nửa vòng trái đất. Bản thân AI đã chậm, nếu mạng còn lag (latency cao), hệ thống CI/CD của bạn chắc chắn sẽ sụp đổ.

Phân tích độ trễ: Kimi suy nghĩ (TTFT) rất nhanh, rào cản lớn nhất gây timeout nằm ở bước thiết lập kết nối TCP/TLS quốc tế.
Gánh nặng Context Window 256K và lãng phí token (Token Waste)
Kimi K2.6 sở hữu Context Window khổng lồ 256,000 tokens. Khả năng này cực kỳ tuyệt vời để nhồi toàn bộ codebase vào một prompt. Tuy nhiên, đẩy một payload nặng vài Megabyte từ Việt Nam qua mạng cáp quang biển quốc tế thường xuyên đứt cáp (như AAG, APG) là một thảm họa.
Giao thức TCP liên tục bị rớt gói (packet loss). Thời gian chờ bị khuếch đại khiến kết nối bị ngắt. Lúc này, script của bạn tự động Retry và gửi lại toàn bộ khối text 256K tokens đó. API không có bộ nhớ cache cho các request đứt gãy, nó sẽ tính phí bạn 2 lần cho phần input, nhưng bạn chỉ nhận về 1 kết quả. Trong các hệ thống chạy hàng nghìn test suite mỗi ngày, độ trễ mạng đẩy hóa đơn cloud tăng lên 30 đến 40% một cách vô lý.
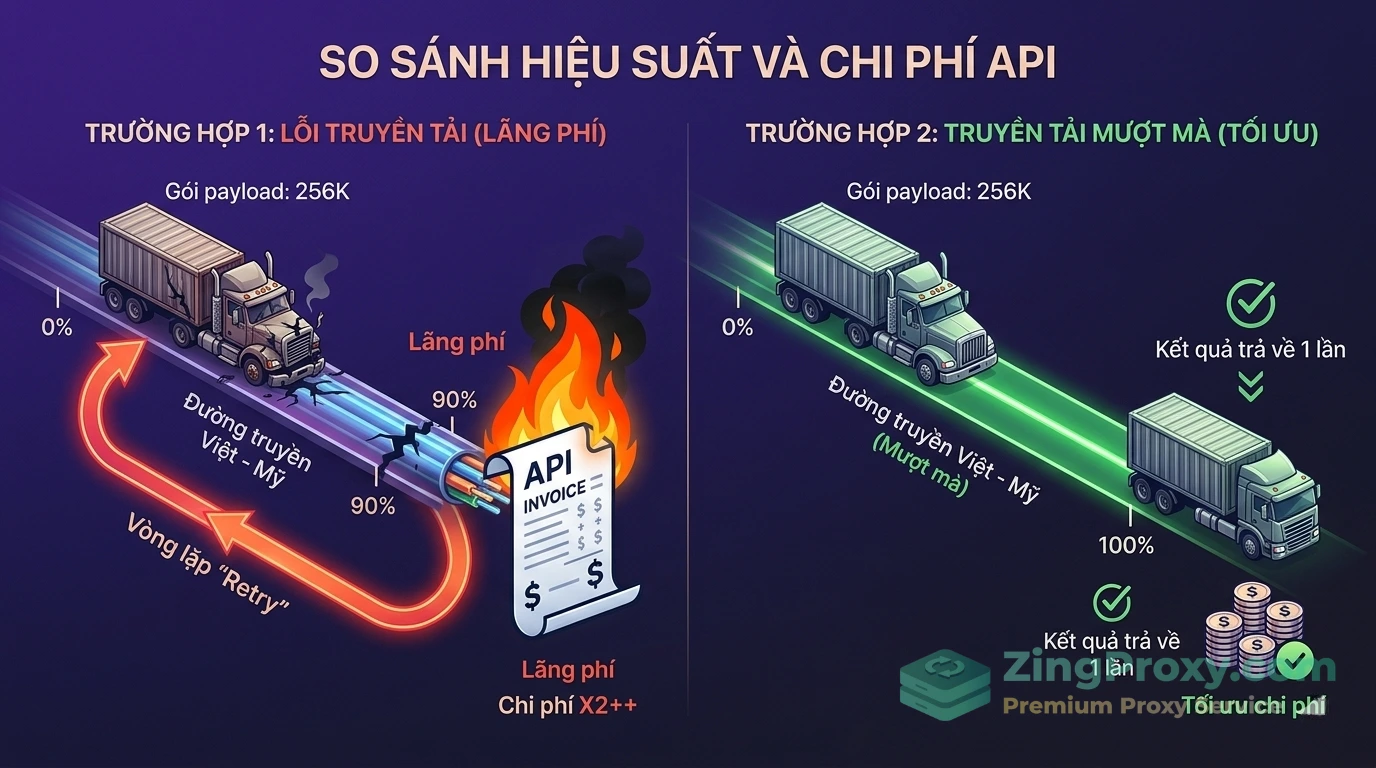
Hiện tượng Token Waste: Khi mạng đứt gãy giữa chừng, hệ thống CI/CD tự động retry khiến hóa đơn API tăng vọt.
Để hiểu sâu hơn về cách phân luồng request khi hệ thống bị quá tải, bạn có thể tham khảo cách cấu hình Reverse Proxy phân tải API để xử lý nghẽn cổ chai cho DeepSeek V4 và Kimi 2.6.
Bản chất kỹ thuật: Tại sao thuê Proxy US lại cứu vãn được latency?
Tại sao từ Việt Nam kết nối trực tiếp API không nhanh, mà định tuyến qua một Proxy Server ở Mỹ rồi mới tới API lại mượt hơn? Câu trả lời nằm ở kiến trúc BGP (Border Gateway Protocol) và Network Peering.
Đường cao tốc Tier-1 ISP và cắt giảm hops mạng
Khi bạn gọi API trực tiếp, giao thức BGP không nhận diện được hiệu năng sẽ đẩy request từ Việt Nam qua 8 đến 12 hops trung chuyển vòng vèo qua Singapore, Hong Kong, Nhật Bản rồi mới vượt Thái Bình Dương. Độ trễ (Ping) trung bình neo ở mức 250ms đến 320ms, thậm chí lên tới 500ms đến 750ms trong quá trình TCP/TLS Handshake.
Ngược lại, khi bạn thuê Proxy US (đặt tại Datacenter Los Angeles hoặc Virginia), request từ Việt Nam chỉ cần một tuyến cáp duy nhất đến Proxy. Từ Proxy đó bắn sang máy chủ API Global của Kimi (được lưu trữ tại Mỹ) chỉ mất 1 đến 2 hops mạng nội bộ (Peering). Khoảng cách chặng cuối này giúp hạ RTT xuống dưới 50ms (tương tự nguyên lý tối ưu VPS Edge Routing kết hợp Proxy SOCKS5 Game Server để giảm latency triệt để). Hạ tầng tại Mỹ xử lý phần việc nặng nhọc nhất, giúp đường truyền cực kỳ ổn định.
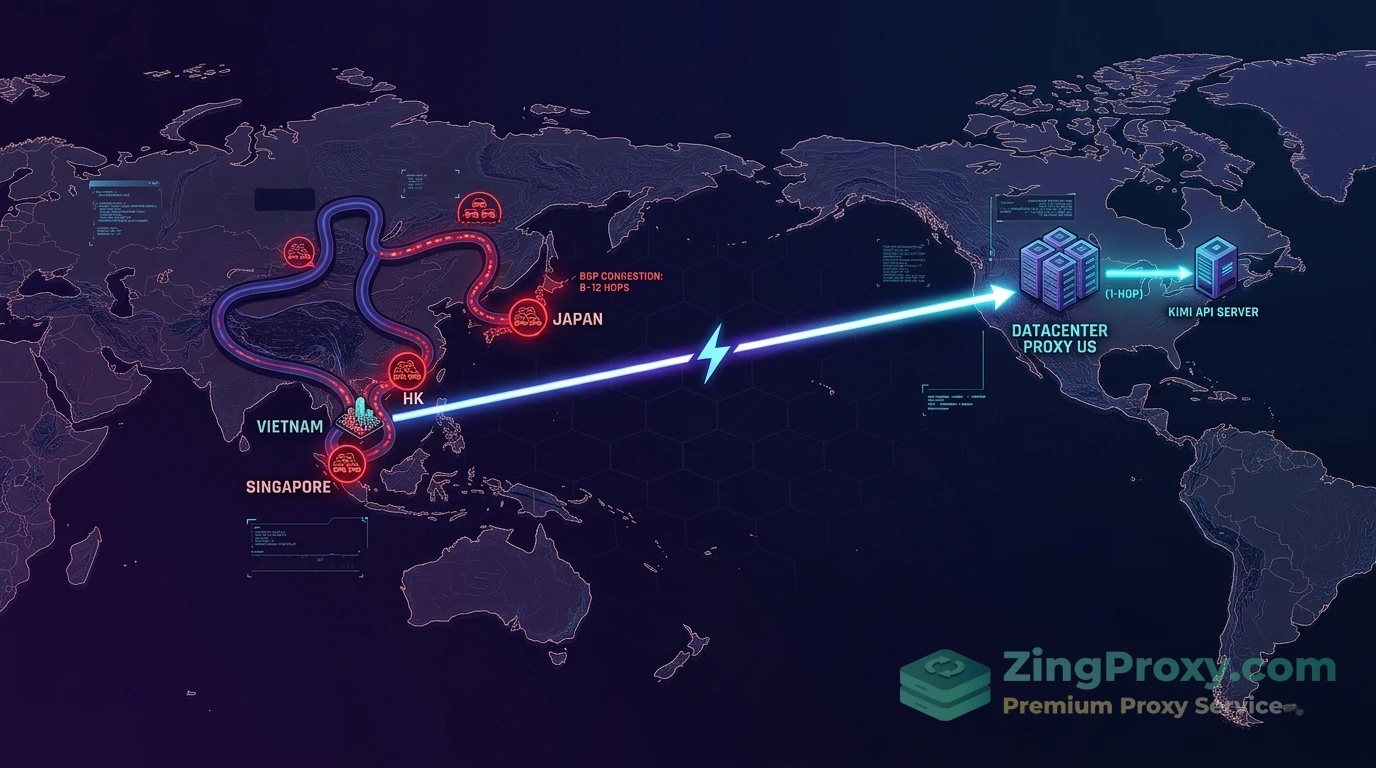
Định tuyến qua Datacenter Proxy US giúp request tránh được các trạm trung chuyển BGP công cộng, đi thẳng vào mạng lưới Tier-1 ISP tốc độ cao.
Datacenter Proxy SOCKS5: Cứu tinh của CI/CD
Tuyệt đối không dùng Residential Proxy (IP dân cư) cho CI/CD vì băng thông thấp và độ trễ cao (cộng thêm 150ms đến 300ms). Hãy chọn Datacenter Proxy (Dedicated IP).
Nếu kịch bản test của bạn cần đọc Streaming Response liên tục, SOCKS5 Proxy là lựa chọn sáng giá (bạn có thể tìm hiểu thêm về những điểm khác biệt giữa SOCKS4 và SOCKS5 để nắm rõ cấu trúc nền tảng). Nó hoạt động ở tầng thấp hơn (Layer 5), truyền phát dữ liệu dưới dạng luồng thô (raw streams) mà không cần parse HTTP headers. Điều này giúp giảm overhead, duy trì luồng text 34 t/s của Kimi ổn định nhất mà không bị bóp băng thông bởi các bộ lọc tầng cao.
Cấu hình Kimi K2.6 chuẩn xác: 3 cái bẫy khiến bạn sập hệ thống
Ngay cả khi sở hữu hạ tầng Proxy tối ưu, nếu bạn cấu hình SDK sai lệch so với tài liệu chính thức, hệ thống vẫn sẽ ném ra lỗi.
Bẫy #1: Endpoint quốc tế (.ai) vs nội địa (.cn)
Kimi cung cấp 2 nền tảng hoàn toàn độc lập (không dùng chung API Key).
- Nội địa Trung Quốc:
https://api.moonshot.cn/v1
- Quốc tế (Global):
https://api.moonshot.ai/v1
Kinh nghiệm: Khi đã định tuyến traffic qua Datacenter Proxy tại Mỹ, bạn BẮT BUỘC phải gọi vào Base URL quốc tế (.ai). Nếu dùng US Proxy nhưng gọi .cn (hoặc ngược lại), bạn sẽ nhận ngay lỗi 401 invalid_authentication_error. Nếu không khai báo base_url, SDK mặc định trỏ về OpenAI và báo lỗi model_not_found.
Bạn có thể đối chiếu thêm danh sách các mã lỗi Proxy phổ biến để biết cách chẩn đoán và khắc phục nhanh chóng.
Bẫy #2: Quên bật stream=True
Nhiều ứng dụng gateway/load balancer trung gian đánh giá kết nối bằng cách chờ nhận status_code và header từ máy chủ. Nếu luồng text của Kimi quá dài và bạn KHÔNG bật chế độ stream, máy chủ phải chờ model gen xong toàn bộ payload mới trả header về. Quá trình chờ đợi này vượt quá timeout của Gateway, dẫn đến việc Gateway tự động ngắt kết nối (báo lỗi Connection Error).
Giải pháp: Bắt buộc cấu hình stream=True để giữ Gateway luôn nhận được luồng dữ liệu liên tục.
Bẫy #3: Tham số temperature khắt khe
Đừng tuỳ tiện thiết lập nhiệt độ. Kimi K2.6 ép buộc:
- Chế độ Thinking (Có suy luận): Bắt buộc
temperature=1.0
- Chế độ Non-thinking: Bắt buộc
temperature=0.6. Truyền bất kỳ số nào khác sẽ lập tức nhận về lỗi API.
Thực chiến: Code mẫu Python kết hợp Proxy US & TCP Keep-Alive
Để tránh rò rỉ dữ liệu hoặc xung đột biến môi trường, cách chuẩn nhất là khởi tạo một httpx.Client tùy chỉnh, thiết lập Connection Pooling (để giữ TCP Keep-Alive), và truyền nó vào SDK.
import httpx
import os
from openai import OpenAI
# 1. Cấu hình Datacenter Proxy US (Dùng SOCKS5 để tối ưu streaming)
# Thêm tiền tố socks5h:// để DNS lookup được thực hiện tại Proxy Server Mỹ
PROXY_URL = os.getenv("US_PROXY_URL", "socks5h://admin:[email protected]:1080")
# 2. Cấu hình Timeout và Connection Pooling (TCP Keep-Alive)
# Điều này chống lỗi ECONNRESET do Gateway ngắt các kết nối Idle
custom_timeout = httpx.Timeout(
connect=10.0,
read=600.0, # Thời gian chờ phản hồi cực dài (rất quan trọng cho API gen token dài)
write=10.0,
pool=10.0
)
limits = httpx.Limits(max_keepalive_connections=20, max_connections=100, keepalive_expiry=30.0)
# Khởi tạo HTTPX Client tùy chỉnh (Bật HTTP/2 Multiplexing nếu server hỗ trợ)
http_client = httpx.Client(
proxies=PROXY_URL,
timeout=custom_timeout,
limits=limits,
http2=True
)
# 3. Khởi tạo API Client (Sử dụng Endpoint Quốc tế .ai)
client = OpenAI(
api_key=os.getenv("KIMI_GLOBAL_API_KEY"),
base_url="https://api.moonshot.ai/v1",
http_client=http_client,
max_retries=3 # Tự động thử lại khi gặp lỗi mạng 408, 429
)
# 4. Hàm thực thi Automation Test
def generate_test_cases(source_code):
try:
response = client.chat.completions.create(
model="kimi-k2.6", # Tên model chuẩn xác
messages=[
{"role": "system", "content": "Bạn là QA Automation, viết test case...!"},
{"role": "user", "content": source_code}
],
temperature=0.6, # Non-thinking mode
stream=True # Bắt buộc: stream=True để chống Gateway Timeout
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
except Exception as e:
print(f"\nLỗi hệ thống hoặc Network Timeout: {e}")
finally:
http_client.close()
Bơm (Inject) Proxy bảo mật vào CI/CD pipeline (GitLab CI & GitHub Actions)
Tuyệt đối không hard-code URL Proxy chứa mật khẩu vào source code. Để đảm bảo pipeline không bao giờ đứt đoạn, Tech Lead nên thiết lập biến môi trường kết hợp thêm kiến trúc High Availability Proxy thông qua hướng dẫn setup tự động failover để đạt uptime 99.9%.
- Với GitHub Actions (Self-hosted Runner): Thiết lập các biến
HTTP_PROXY, HTTPS_PROXY vào file /etc/environment (trên Linux) hoặc file .env cục bộ. Runner sẽ tự động nhận diện.
- Với GitLab CI (GitLab Runner): Chỉnh sửa file
config.toml trên máy chủ Runner. Thêm vào mảng environment: environment = ["HTTP_PROXY=socks5h://user:[email protected]:1080"].
- Với Shared/Cloud Runners: Lưu Proxy credentials vào hệ thống quản lý Secret (Masked/Protected Variables). Trong
.gitlab-ci.yml, gọi ra bằng lệnh export HTTP_PROXY=http://${{ secrets.PROXY_USER }}:${{ secrets.PROXY_PASS }}@${{ secrets.PROXY_URL }}. Logs hệ thống sẽ tự động mã hóa (mask) các thông tin này. Mặc dù hệ thống không thể hiển thị sơ đồ mạng ở đây, nhưng qua những kiến thức thực tiễn trên, có thể thấy việc sử dụng Proxy US mang lại lợi ích to lớn thế nào.
Bài toán ROI: Đáng giá từng xu
Sự kết hợp giữa Proxy US, TCP Keep-Alive, và Cấu hình SDK chuẩn mang lại hiệu quả tức thì:
- Triệt tiêu Flaky Test: Tỉ lệ timeout giảm xuống 0%. Bạn không còn phải đọc các log lỗi mạng vô nghĩa và gỡ rối sai hướng.
- Tối ưu Hops và TCP Handshake: Proxy duy trì các luồng mở liên tục (persistent connections). Các request sau sẽ được đẩy đi ngay lập tức, cắt bỏ 60 đến 80% thời gian thiết lập kết nối Handshake.
- Bù đắp nhược điểm Model: Giảm RTT từ ~450ms xuống ~50ms. Thời gian tiết kiệm được này giúp bù đắp hoàn hảo cho chỉ số TTFT 3.04s chậm chạp của mô hình.
- Tiết kiệm chi phí: Xóa sổ hiện tượng Token Waste do Retry, tiết kiệm tới 15% tổng hóa đơn Cloud. Đây cũng là nền tảng cốt lõi trong chiến lược Model Routing và tối ưu hạ tầng token sau khi so sánh các AI cho lập trình năm 2026.
Chi phí cho một IP Datacenter tĩnh tại Mỹ chỉ ngang một cốc cà phê, nhưng đổi lại, nó cứu vãn hàng trăm giờ Idle Time của toàn bộ team Dev & QA.

Hiệu quả thực tế (ROI): Thuê Proxy US Datacenter không chỉ tối ưu RTT mà còn cứu vãn hàng trăm giờ chờ đợi pipeline của team Tech.
Câu hỏi thường gặp (FAQ)
1. Tại sao chạy test code với Kimi K2.6 hay bị lỗi Timeout (Connection Error) dù đã tăng biến timeout trong code?
Mạng lag cộng với tốc độ nhả chữ chậm (34 tokens/s) của model khiến các Gateway trung gian tưởng kết nối đã mất nên tự ngắt (ECONNRESET).
Giải pháp: Luôn bật stream=True và cấu hình TCP Keep-Alive qua Proxy.
2. Tôi nên thuê proxy us loại Datacenter hay Residential (IP dân cư) để chạy CI/CD?
Bắt buộc dùng Datacenter Proxy (Dedicated IP). Proxy dân cư băng thông thấp, ping cao, dễ mất kết nối, chỉ hợp để thu thập dữ liệu (scraping) chứ không gánh nổi cường độ của luồng CI/CD.
3. Tại sao đã thuê Proxy US nhưng vẫn bị lỗi 401 invalid_authentication_error hoặc model_not_found?
Do gọi sai Base URL. Khi dùng Proxy Mỹ, hệ thống nhận diện bạn là user quốc tế. Bạn phải gọi vào Endpoint Global (https://api.moonshot.ai/v1). Nếu gọi vào .cn hoặc để trống (mặc định trỏ về OpenAI), API sẽ từ chối.
4. Giao thức Proxy nào tốt nhất cho Kimi API: HTTP/HTTPS hay SOCKS5?
SOCKS5 Proxy. Vì Kimi API dùng cơ chế Streaming liên tục, SOCKS5 (hoạt động ở Layer 5) sẽ truyền luồng dữ liệu thô (raw streams) mà không tốn tài nguyên parse HTTP headers, giúp tối ưu overhead cực tốt.
5. Khi cấu hình Kimi K2.6 SDK, tham số temperature nên đặt là bao nhiêu?
Kimi K2.6 ép buộc giá trị cố định, không được tùy chỉnh:
- Chế độ Thinking (Suy luận): Bắt buộc
temperature=1.0.
- Chế độ Non-thinking: Bắt buộc
temperature=0.6.
Truyền bất kỳ số nào khác hệ thống sẽ báo lỗi.
Kết luận
Kimi K2.6 là một cỗ máy reasoning mạnh mẽ nhưng có phần chậm chạp với các luồng payload khổng lồ 256K. Nhồi dữ liệu đó qua một đường truyền cáp quang quốc tế đầy rủi ro và mong đợi nó trả kết quả ngay lập tức là một tư duy sai lầm về mặt thiết kế hệ thống.
Thay vì tranh cãi về logic của LLM, hãy giải quyết bài toán vật lý trước. Việc thuê Proxy US để định tuyến lưu lượng vào các mạng Tier-1 ISP, kết hợp cùng việc chọn đúng Endpoint (.ai), thiết lập stream=True, cấu hình temperature chính xác và áp dụng TCP Keep-Alive chính là giải pháp cốt lõi cho hệ thống của bạn. Đã đến lúc gỡ bỏ nút thắt cổ chai và nhìn CI/CD của bạn trở lại trạng thái Passed (xanh)!
Tài liệu tham khảo