Mở dashboard quản lý chi phí API cuối tháng lên, chắc hẳn không ít Tech Lead đang phải đau đầu. Bạn tích hợp API key tốt nhất vào IDE cho các developer, và kết quả là hóa đơn token tăng phi mã. Có những ngày, hệ thống CI/CD tự động sập nguồn chỉ vì AI nội bộ sinh ra hàng loạt sub-agents thu thập dữ liệu, khiến IP công ty bị cảnh báo rate-limit. Hoặc có những lúc developer gửi lên một tấm ảnh chụp màn hình UI lỗi chưa downsample, và đột nhiên tài khoản tiêu hao lượng token gấp 3 lần bình thường vì AI cố gắng phân tích độ phân giải gốc.
Giữa cơn bão chi phí và rào cản hạ tầng mạng này, việc tìm kiếm một bài đánh giá so sánh AI cho lập trình chỉ dựa trên điểm số benchmark thuần túy là không đủ. Bài viết này sẽ phân tích sức mạnh thực sự của 5 mô hình lập trình hàng đầu năm 2026 (GPT-5.5, GLM-5.1, Claude Opus 4.7, DeepSeek V4, Kimi K2.6), xem xét cách chúng tư duy, gỡ lỗi ra sao, và quan trọng nhất là làm thế nào để setup một kiến trúc Model Router qua VPS/Proxy nhằm tối ưu ngân sách của bạn.
Đại chiến thông số & bảng giá API (Specs & TCO)
Trước khi bàn về độ thông minh, hãy đặt các mô hình này lên bàn cân kinh tế. Dưới đây là bức tranh toàn cảnh về thông số kỹ thuật và cước phí API (trên 1 triệu tokens) được cập nhật mới nhất vào tháng 4/2026.
| Mô hình |
Context Window |
Tổng tham số |
Tham số kích hoạt (Active) |
License |
Giá API / 1M Token (Input / Output / Cache Hit) |
| GPT-5.5 |
1,000,000 |
Kín |
Kín |
Proprietary |
Input: $5.00
Output: $30.00
Cache Hit: $0.50 |
| Claude Opus 4.7 |
1,000,000 |
Kín |
Kín |
Proprietary |
Input: $5.00
Output: $25.00
Cache Hit: $0.50 |
| GLM-5.1 |
~203K |
754B |
40B |
MIT |
Input: $1.40
Output: $4.40
Cache Hit: $0.26 |
| Kimi K2.6 |
256K |
1T |
32B |
Modified MIT |
Input: $0.95
Output: $4.00
Cache Hit: $0.16 |
| DeepSeek V4 Pro |
1,000,000 |
1.6T |
49B |
MIT |
Input: $1.74
Output: $3.48
Cache Hit: $0.0145 |
| DeepSeek V4 Flash |
1,000,000 |
284B |
13B |
MIT |
Input: $0.14
Output: $0.28
Cache Hit: $0.0028 |
(Lưu ý: Kimi K2.6 nếu dùng qua các kênh phân phối proxy có thể giảm giá chỉ còn $0.60 Input / $2.40 Output. DeepSeek V4 Pro đang có đợt giảm giá 75% cho đến hết 31/05/2026, kéo giá Input Cache Hit xuống mức tối ưu là $0.003625).
Nghịch lý Giá API và Hiệu quả Token
Nhìn vào bảng trên, DeepSeek V4 Pro đang là mô hình tối ưu chi phí nhất với hiệu năng Token-to-Cost vượt trội (giá Output chỉ $3.48 so với $25 của Claude 4.7). Thế nhưng, trong thực chiến Agentic AI, GPT-5.5 lại đang chứng minh một bài toán kinh tế khác.
Mặc dù giá niêm yết đắt đỏ, GPT-5.5 sinh ra ít hơn tới 72% số token đầu ra so với Claude Opus 4.7. GPT-5.5 không tường thuật dài dòng, nó chỉ trả về một tight diff (đoạn code thay đổi tối thiểu). Do đó, trong một quy trình CI/CD tự động gọi API hàng chục lần, khả năng nói ít làm nhiều của GPT-5.5 giúp bạn không bị tràn ngữ cảnh (context rot) và thực tế có thể tiết kiệm chi phí vận hành hơn so với các mô hình dài dòng.

Ma trận so sánh ROI (Tỷ suất hoàn vốn) giữa các dòng mô hình AI mã nguồn đóng và mở.
Phân tích thực chiến: Cách 5 mô hình giải quyết Task
Các bài test trên giấy không phản ánh được áp lực thực tế khi codebase phình to lên hàng trăm nghìn dòng. Mỗi mô hình trong năm 2026 đều chọn một triết lý Agentic AI hoàn toàn riêng biệt.
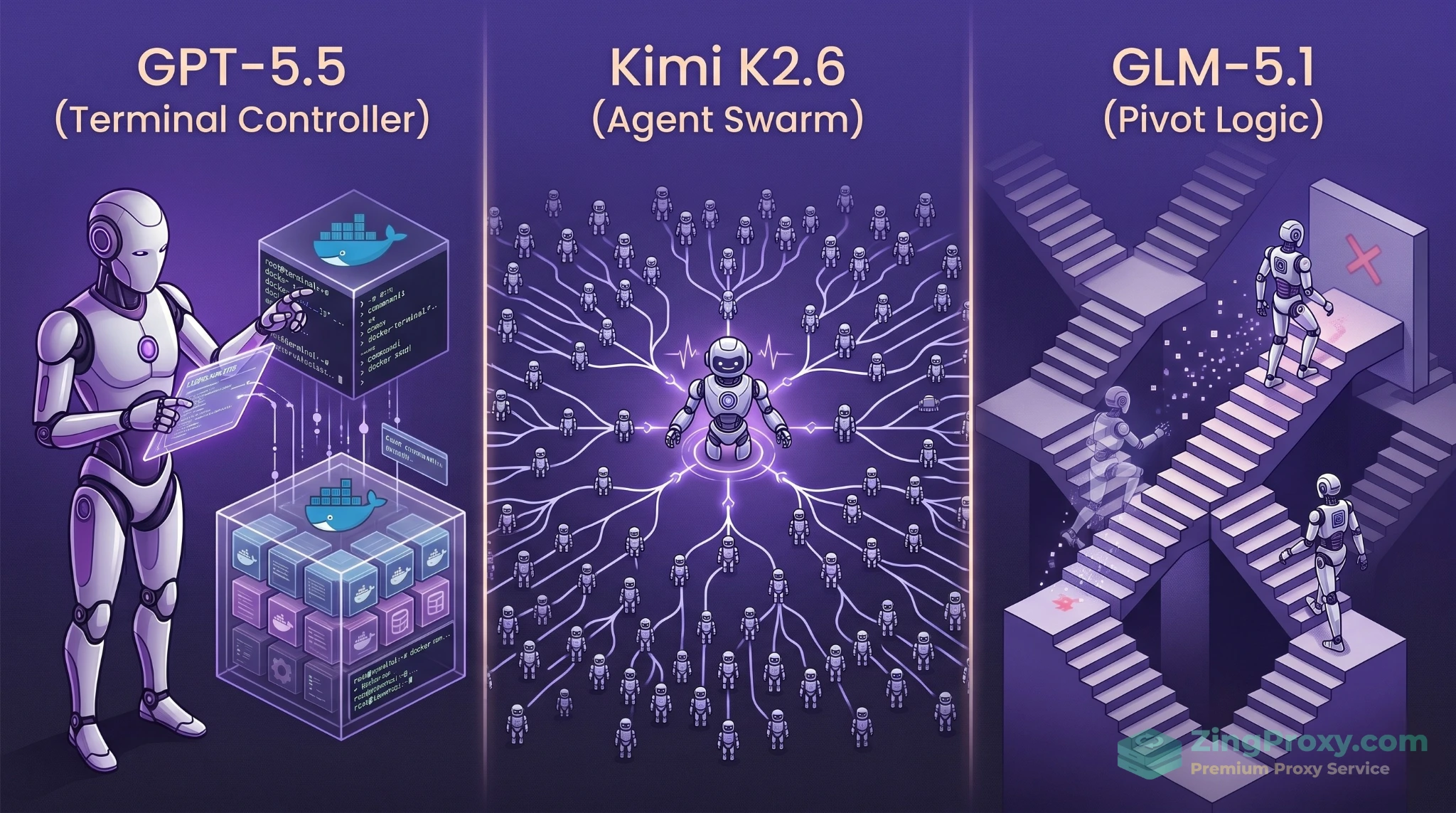
Trực quan hóa cách các AI thế hệ mới xử lý quy trình làm việc tự trị (Agentic Workflow).
GPT-5.5: Lập trình viên đơn độc thao tác Terminal
GPT-5.5 tiếp cận Agentic AI theo hướng kiểm soát sâu vào hệ thống. Với điểm số kỷ lục 82.7% trên Terminal-Bench 2.0, GPT-5.5 không chỉ sinh ra text. Nó tự động mở Terminal, chạy môi trường sandbox Docker, cài đặt package, thực thi lệnh npm install, đọc stack traces (thông báo lỗi) và tự động lặp lại vòng lặp vá lỗi cực nhanh. Đây là mô hình sinh ra để gánh vác tự động hóa toàn phần mà không cần con người ngồi giám sát từng bước.
Kimi K2.6: Bậc thầy điều phối Agent Swarm
Đạt 58.6% trên SWE-Bench Pro (vượt qua mức 53.4% của Claude 4.6/4.7 trong bài test tương ứng), Kimi K2.6 không hoạt động đơn độc. Cốt lõi của nó là Agent Swarm. Kimi K2.6 có thể chia nhỏ tác vụ và điều phối tới 300 tác nhân phụ (sub-agents) chạy song song qua 4.000 bước.
Case study kinh điển: Kimi K2.6 đã từng tự động phân tích biểu đồ ngọn lửa (flame graphs) của một engine tài chính exchange-core 8 năm tuổi. Nó nhận diện nút thắt cổ chai và tự tin cấu trúc lại thread topology (cấu trúc luồng) từ 4ME+2RE sang 2ME+1RE. Kết quả là thông lượng xử lý tăng vọt 185% (lên 1.24 MT/s) trong một phiên làm việc dài 13 giờ. Độ chính xác như phẫu thuật này khiến nó trở thành công cụ đắc lực cho việc refactor các hệ thống di sản (legacy code).
GLM-5.1: Cỗ máy lỳ lợm thoát khỏi ngõ cụt
Sở hữu điểm SWE-Bench 58.4%, GLM-5.1 mang đến khả năng sinh tồn cực cao trong các task kéo dài. Trong khi phần lớn AI bị kẹt vào vòng lặp lỗi (infinite loop) sau 50 lần thử sai, GLM-5.1 có thể tự trị độc lập suốt 8 giờ. Điểm mạnh nhất của nó là nhận biết ngõ cụt (dead ends). Nó đánh giá kết quả tạm thời và sẵn sàng vứt bỏ hoàn toàn một phương pháp sai lầm để chuyển hướng (pivot) sang một luồng tư duy mới. Do đó, GLM-5.1 được tin dùng tuyệt đối cho các tác vụ kiểm toán bảo mật (Security Audit) hay rà soát kiến trúc hệ thống chuyên sâu.
Claude Opus 4.7: Kiến trúc sư gỡ lỗi Race Condition
Khi đối mặt với các bẫy dữ liệu mâu thuẫn (dissonant-data traps) hoặc yêu cầu khả năng suy luận logic siêu dài, Claude Opus 4.7 vẫn là một tượng đài. Sự tin cậy của nó thể hiện qua việc vượt qua 3 bài test TBench mà các đối thủ không thể giải quyết. Đặc biệt, Opus 4.7 đã vá thành công lỗi Tương tranh / Cạnh tranh luồng (Race Condition) cực kỳ phức tạp. Nếu hệ thống của bạn yêu cầu một bộ não đủ sắc bén để thiết kế Database Schema từ đầu mà không bị ảo giác (hallucination), Claude Opus 4.7 là lựa chọn duy nhất.
Lưu ý: Nếu thấy Opus 4.7 tốn token hơn trước, đó là do nó đã được nâng cấp độ phân giải hình ảnh cực cao. Hãy sử dụng kỹ thuật downsample ảnh trước khi gửi API để kiểm soát chi phí.
DeepSeek V4 Pro: Tối ưu kiến trúc cho siêu kho mã
Sở hữu 1.6T tham số (nhưng chỉ active 49B), DeepSeek V4 Pro đạt điểm số 93.5 trên LiveCodeBench. Khi xử lý kho mã lên tới 1 triệu token, nó áp dụng kiến trúc Hybrid Attention (CSA + HCA) giúp giảm thiểu 27% số FLOPs tính toán và 10% dung lượng KV Cache so với thế hệ V3.2. Điều này giúp V4 nạp toàn bộ repo backend khổng lồ để tìm kiếm dependencies với tốc độ chớp nhoáng mà giá thành lại siêu rẻ.
Lựa chọn AI theo use-case thực tế của team
Một bài đánh giá so sánh AI cho lập trình đúng nghĩa phải giúp bạn chọn đúng công cụ cho đúng bài toán. Việc lạm dụng tài nguyên không cần thiết sẽ chỉ làm cạn kiệt ngân sách của bạn.
- Nhóm Startup (Ưu tiên giá & Ngân sách hạn hẹp): DeepSeek V4 Flash & Kimi K2.6
Với mức giá Output chỉ $0.28/1M token, DeepSeek Flash rẻ hơn Claude 4.7 tới gần 90 lần. Nó lý tưởng để sinh boilerplate code, format JSON hay gen Unit Test hàng loạt. Kimi K2.6 với tính năng Agent Swarm giúp bạn triển khai tự động hóa quy mô lớn mà không cần tuyển thêm nhân sự.
- Nhóm Scale-up (Ưu tiên tốc độ & Thông lượng cao): GPT-5.5
Khi đội ngũ phình to, thời gian thực thi (Wall-clock time) là vàng. GPT-5.5 với đặc tính nói ít làm nhiều giúp giảm 72% output token, loại bỏ các diễn giải dài dòng, giúp các kịch bản CI/CD chạy mượt mà và tránh tràn ngữ cảnh.
- Nhóm Fintech & Banking (Ưu tiên Data Residency & Bảo mật): DeepSeek V4 Pro & GLM-5.1
Hai mô hình này cung cấp trọng số nguồn mở (open-weights) dưới giấy phép MIT. Team Security hoàn toàn có thể đem chúng về tự host trên máy chủ vật lý nội bộ (On-premise / Air-gapped), tuân thủ 100% chủ quyền dữ liệu, không cho phép bất kỳ dòng code nhạy cảm nào lọt ra ngoài.
- Nhóm GitHub Team (Ưu tiên Workflow & Tích hợp công cụ): Claude Opus 4.7
Khả năng tích hợp sâu qua các MCP Server giúp Claude 4.7 hoạt động như một reviewer tự động. Nó có thể đọc Pull Request, gỡ rối merge conflict trực tiếp trên môi trường GitHub cực kỳ uyển chuyển.
- Large Codebase (Ưu tiên xử lý siêu ngữ cảnh): DeepSeek V4 Pro
Nếu bạn có một dự án Monolithic khổng lồ, khả năng tiêu thụ cực ít tài nguyên (chỉ 10% KV Cache) của DeepSeek V4 Pro khi nạp đủ 1 triệu token giúp bạn tra cứu toàn bộ repo mà không làm cháy bộ nhớ server.
- Team Việt Nam / Outsource (Hỗ trợ Ngôn ngữ): Kimi K2.6 & Claude 4.7 (Custom config)
Kimi K2.6 được huấn luyện xuất sắc với dữ liệu châu Á, cực kỳ nhạy bén khi review các dự án chứa comment code đa ngôn ngữ. Đối với Claude 4.7, developer Việt có thể kích hoạt biến môi trường CLAUDE_CODE_NO_FLICKER để tránh lỗi giật lag khi gõ tiếng Việt trên Terminal.
Tối ưu TCO: Giải pháp hạ tầng, Proxy & VPS cứu cánh ngân sách
Đây là phần quan trọng nhất dành cho các Tech Lead. Đừng phó mặc toàn bộ quy trình cho các nhà cung cấp API. Việc kết hợp hạ tầng VPS và Proxy sẽ thay đổi hoàn toàn bài toán ngân sách của bạn (giảm đến 90% TCO).
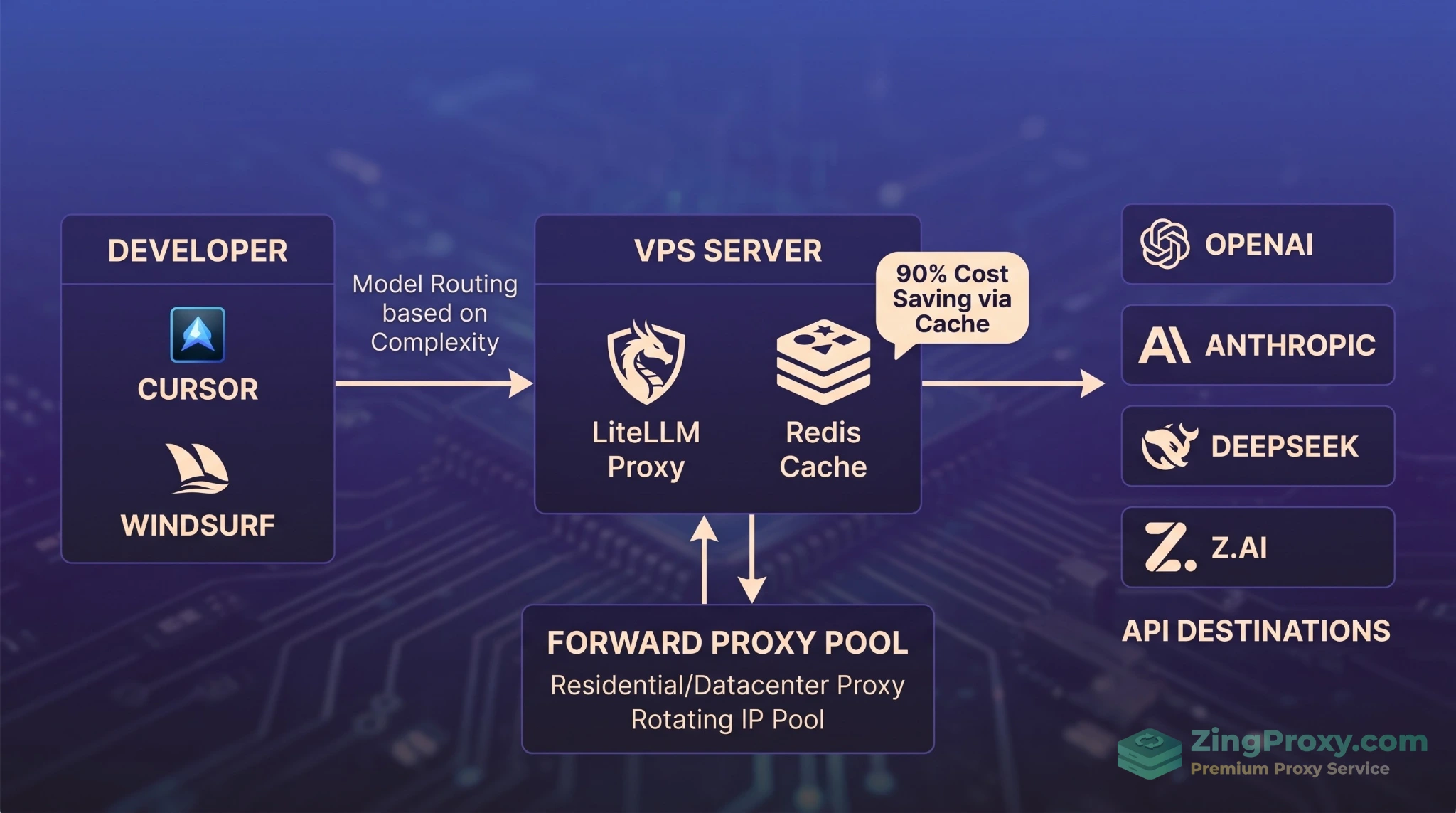
Mô hình triển khai AI Pipeline thực chiến giúp doanh nghiệp tiết kiệm đến 90% chi phí vận hành.
Triển khai Python Model Router trên VPS (Local LiteLLM)
Hard-code API Key của một model đắt đỏ vào toàn bộ hệ thống là một rủi ro lớn về chi phí. Thay vào đó, hãy thuê một chiếc VPS Linux ổn định và cài đặt Local LiteLLM Proxy Server. VPS này sẽ hoạt động như một AI Gateway điều phối mọi request từ IDE của Dev (bạn có thể tham khảo thêm cách cấu hình Proxy Ubuntu 26.04 hiệu năng cao để tối ưu máy chủ).
- Tiền tính toán: Router viết bằng Python sẽ đánh giá nhanh metadata của request (độ dài, CodeHealth, mức độ phức tạp).
- Định tuyến (Routing): Nếu tác vụ dễ (ví dụ autocomplete, viết comment), request lập tức được định tuyến ngầm qua DeepSeek V4 Flash ($0.14 input). Nếu mã nguồn lộn xộn hoặc đòi hỏi tư duy kiến trúc sâu, router mới mở cửa đẩy request sang Claude Opus 4.7 ($5.00 input).
- Fallback (Chuyển hướng dự phòng): Nếu DeepSeek thất bại sau vài lần thử (Verification Gate không pass), router tự động chuyển sang mô hình đắt tiền hơn. Giải pháp này giúp cắt giảm 70% hóa đơn hàng tháng mà Dev không cần phải tự thao tác chuyển đổi mô hình.
Khai thác sức mạnh của Forward Proxy trong quản lý luồng dữ liệu
Khi bạn dùng tính năng Agent Swarm (của Kimi K2.6) thu thập dữ liệu hoặc tương tác với Git, hàng trăm agents sẽ gửi request liên tục. Để quản lý hiệu quả lưu lượng mạng và đảm bảo tính liên tục của hệ thống nội bộ, máy chủ chạy Agent nên được cấu hình đi qua một Forward Proxy (Datacenter hoặc Residential Proxy).
Hệ thống Load Balancer trên VPS sẽ điều phối kết nối một cách tối ưu. Điều này giúp cân bằng tải mạng lưới, giữ kết nối ổn định đến các trang đích và đảm bảo hệ thống tự động hóa của bạn hoạt động mượt mà 24/7.
Kết hợp tối ưu: Prompt Caching & Message Batches API
- Prompt Caching: Khi nạp hàng ngàn file code làm ngữ cảnh nền, tính năng Caching của Anthropic hoặc DeepSeek giúp lưu trữ cấu trúc tĩnh này. Khi cache hit, bạn tiết kiệm tới 90% chi phí input token (Ví dụ: DeepSeek Pro chỉ còn $0.003625/1M token).
- Message Batches API (Chạy ngầm): Nếu bạn cần review hàng loạt file code hoặc sinh Unit Test định kỳ vào ban đêm, đừng dùng API thời gian thực. Hãy thiết lập VPS gom yêu cầu thành file JSONL và bắn qua Batch API. Chấp nhận chờ đợi kết quả xử lý bất đồng bộ (khoảng 24 giờ), nhưng bù lại OpenAI và Anthropic sẽ giảm giá trực tiếp 50% cho hóa đơn token của bạn.
Data Residency: Bài toán tự Host (On-premise) bằng VPS GPU
Doanh nghiệp bảo mật cao không thể gửi dữ liệu ra Cloud? DeepSeek V4 Flash hiện tại có thể chạy cực êm trên cụm server nội bộ chứa 4x RTX 4090 (96GB VRAM) với tốc độ 15-20 token/giây. Đối với bản DeepSeek V4-Pro, bạn sẽ cần thiết lập cụm VPS GPU lớn trang bị kiến trúc H100. Việc trả chi phí cố định để thuê/mua VPS GPU giúp bạn có môi trường Air-gapped hoàn toàn an toàn, giải quyết dứt điểm cơn đau đầu về pháp lý bảo mật (Compliance).
Câu hỏi thường gặp (FAQ)
1. Trong các bài đánh giá so sánh AI cho lập trình, GPT-5.5 hay Claude Opus 4.7 mới là mô hình tốt nhất?
Tùy mục đích. GPT-5.5 tối ưu chi phí, nhanh, tự chạy Terminal cực tốt cho CI/CD (giảm 72% token đầu ra). Claude Opus 4.7 suy luận sâu, phù hợp để thiết kế hệ thống và sửa các bug phức tạp (như Race Condition).
2. Mô hình AI nào viết code tối ưu chi phí nhất 2026?
DeepSeek V4 Flash. Với mức giá Output chỉ $0.28/1M token, nó tối ưu chi phí hơn Claude 4.7 gần 90 lần. Đây là lựa chọn hoàn hảo cho các Startup cần sinh boilerplate code hoặc Unit Test số lượng lớn.
3. Tại sao DeepSeek V4 lại có mức giá tối ưu mà code vẫn tốt?
Nhờ kiến trúc MoE (Mixture of Experts) và Hybrid Attention. Bản V4-Pro có tới 1.6T tham số nhưng chỉ kích hoạt 49B tham số khi chạy, giúp giảm 27% lượng tính toán (FLOPs) mà vẫn giữ được độ thông minh ngang ngửa các mô hình đắt tiền.
4. Tại sao dạo gần đây Claude Opus 4.7 lại tiêu tốn nhiều token API hơn bình thường?
Do tính năng xử lý ảnh (Vision) được mặc định đẩy lên độ phân giải cực cao để soi chi tiết. Cách khắc phục: Lập trình viên nên chủ động downsample (giảm độ phân giải) ảnh trước khi gửi, và dùng Prompt Caching để tiết kiệm chi phí.
5. Cách quản lý kết nối mạng khi dùng AI Agent / Agent Swarm công suất lớn?
Việc sử dụng Forward Proxy là giải pháp hạ tầng cần thiết. Bằng cách tối ưu hạ tầng AI Agent bằng Proxy dân cư xoay vòng, hệ thống sẽ phân bổ hợp lý các request từ AI Agent. Điều này giúp duy trì đường truyền mạng ổn định khi giao tiếp với GitHub hay API Provider, tránh tắc nghẽn cục bộ và đảm bảo hệ thống tự động hóa hoạt động liên tục.
6. Yêu cầu phần cứng để tự host (On-premise) DeepSeek V4 hay GLM-5.1 là gì?
Bản nén (DeepSeek V4-Flash) cần Server gắn 4x RTX 4090 (96GB VRAM). Bản nặng (DeepSeek V4-Pro, GLM-5.1) bắt buộc dùng hệ thống VPS GPU cỡ lớn kiến trúc NVIDIA H100. Đừng quên kết hợp Private Proxy Remote Work và SSO để team dev truy cập server nội bộ từ xa an toàn.
Kết luận
Bức tranh công nghệ 2026 đã chứng minh rằng: Việc so sánh AI cho lập trình giờ đây không còn để tìm ra một vị trí độc tôn duy nhất. Chiến thắng thuộc về những đội ngũ biết thiết lập một Tech Stack AI linh hoạt:
Hãy dùng DeepSeek V4 / Kimi K2.6 làm cơ bắp để gánh vác khối lượng lớn, dùng GPT-5.5 làm đôi tay thao tác cực nhanh ít tốn token, và dùng Claude Opus 4.7 / GLM-5.1 làm bộ não giải quyết những bài toán cốt lõi nhất. Đặc biệt, đừng bao giờ quên trang bị một tấm khiên định tuyến vững chắc bằng hệ thống VPS và Proxy chuyên nghiệp. Đó chính là chìa khóa tối thượng để vận hành AI mạnh mẽ, an toàn và tối ưu chi phí trong một thế giới kỹ thuật số đầy cạnh tranh.
Tài liệu tham khảo