Bạn setup một hệ thống thu thập dữ liệu hoạt động mượt mà cả đêm, đinh ninh sáng dậy sẽ có hàng triệu record hoàn chỉnh nằm gọn trong database. Thế nhưng, sáng mở log ra thì thấy dày đặc lỗi ECONNRESET hoặc dính hàng loạt mã 429 Too Many Requests. Nhìn kỹ lại thì hóa ra một nested query (truy vấn lồng nhau) chạy quá lâu đã làm đứt gãy toàn bộ socket, hoặc server đã block IP vì bạn vô tình truy xuất vượt giới hạn Query Complexity.
Thu thập dữ liệu từ REST API đã tốn nhiều công sức, xử lý các endpoint GraphQL hiện đại còn dễ khiến các Data Engineer và Backend Developer gặp nhiều khó khăn hơn.
Vậy làm thế nào để duy trì một luồng kết nối xuyên suốt (persistent connection), trích xuất hàng chục nghìn record qua mạng lưới proxy mà không lo đứt gãy giữa chừng? Bài viết này sẽ phân tích chi tiết giải pháp Web Scraping GraphQL ở cấp độ Enterprise, kết hợp kiến trúc I/O bất đồng bộ của Node.js (engine Undici mới nhất) cùng giao thức SOCKS5 Proxy.
Tại sao Web Scraping GraphQL lại phức tạp hơn REST API?
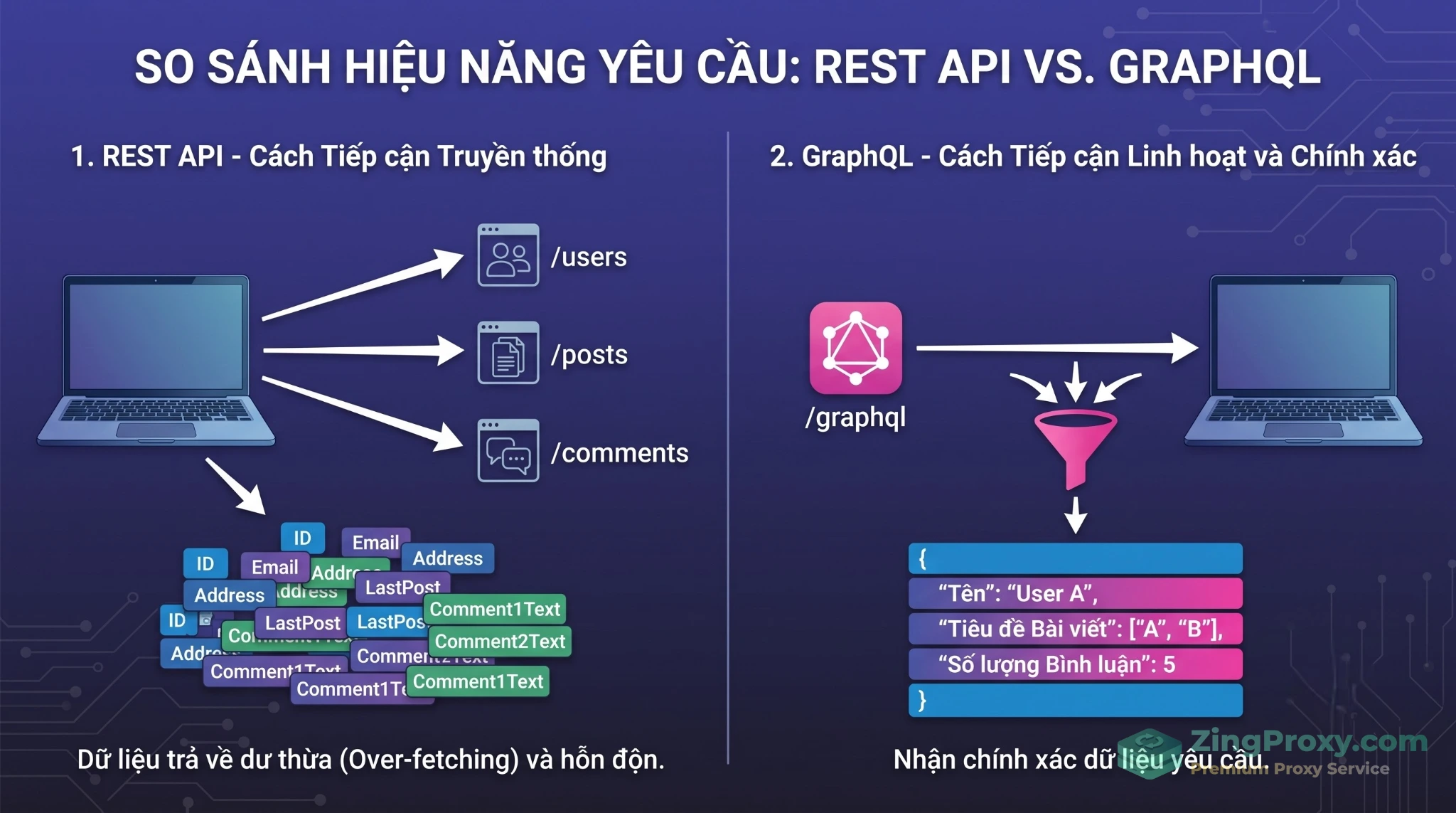
Với REST API, bạn có hàng tá endpoint rõ ràng (ví dụ: /users, /posts). Khi cần thu thập dữ liệu, bạn cứ gọi tuần tự từng đường dẫn. Tuy nhiên, GraphQL thay đổi hoàn toàn luật chơi khi gom tất cả lưu lượng về một endpoint duy nhất (thường là POST /graphql). Nhìn thì gọn, nhưng thực tế triển khai lại ẩn chứa nhiều rủi ro sập luồng.
Lợi thế Introspection (nếu mở) và cách Reverse Engineering payload
Trong GraphQL có một tính năng cốt lõi gọi là Introspection (Tự xem xét). Tính năng này cho phép client hỏi thẳng server: Hệ thống đang có những bảng dữ liệu nào, các trường ra sao?.
Nếu các developer vô tình quên tắt tính năng này trên môi trường Production, đây sẽ là lợi thế lớn để bạn ánh xạ toàn bộ kiến trúc dữ liệu bằng một truy vấn __schema đơn giản. Tuy nhiên, với các hệ thống bảo mật tốt, Introspection sẽ bị vô hiệu hóa. Lúc này, bạn bắt buộc phải dùng kỹ thuật Reverse Engineering (dịch ngược) payload.
Cách làm rất thực chiến:
Mở Chrome DevTools (F12) > Tab Network.
Filter với từ khóa graphql.
Bấm vào một request và xem thẻ Payload.
Bạn sẽ thấy một khối JSON chứa 3 thành phần quan trọng:
operationName: Tên truy vấn (ví dụ: GetProductList). Server thường dùng thông số này để ghi log hoặc rate-limit, nếu bạn gửi request mà thiếu nó, khả năng cao sẽ bị block.
query: Cấu trúc raw string chứa các trường cần lấy.
variables: Object chứa các tham số truyền vào động (như limit, cursor).
Ám ảnh Connection Timeout và giới hạn Query Complexity
Khác với REST (giới hạn dựa trên số lượng request HTTP), GraphQL giới hạn tốc độ dựa trên Query Complexity (Độ phức tạp của truy vấn).
Hệ thống đánh giá cost (chi phí) cho mỗi object. Nếu bạn thiết lập một nested query cực sâu (Ví dụ: Lấy Danh mục -> Lấy Sản phẩm -> Lấy Review -> Lấy User review), số lượng truy vấn cơ sở dữ liệu ngầm (hiện tượng N+1) sẽ tăng theo cấp số nhân.
Hậu quả là bạn không cần gửi hàng nghìn request HTTP. Chỉ cần 1-2 request chứa query quá nặng, bạn sẽ dùng cạn kiệt Cost Budget của server và ngay lập tức nhận mã lỗi 429 Too Many Requests. Để xử lý triệt để vấn đề này, bạn có thể tham khảo các phương pháp giải quyết triệt để lỗi Rate Limit API. Tồi tệ hơn, các query nặng xử lý quá lâu sẽ làm vượt quá thời gian chịu đựng của TCP socket, dẫn tới Connection Timeout làm sập toàn bộ Data Pipeline.
Khác với REST API gọi nhiều endpoint, GraphQL tập trung luồng dữ liệu qua một cổng duy nhất, giúp tối ưu băng thông nhưng lại dễ bị đánh dấu (rate-limit) nếu truy vấn quá nặng.
SOCKS5 Proxy: mảnh ghép hoàn hảo cho Persistent Connection
Khi scale hệ thống thu thập dữ liệu lên hàng triệu request, việc luân chuyển (rotate) request qua Proxy là bắt buộc. Nhưng để tối ưu pipeline cho GraphQL, HTTP Proxy truyền thống không phải là lựa chọn khôn ngoan.
Hoạt động ở tầng Transport (TCP/UDP), tối ưu hơn HTTP Proxy
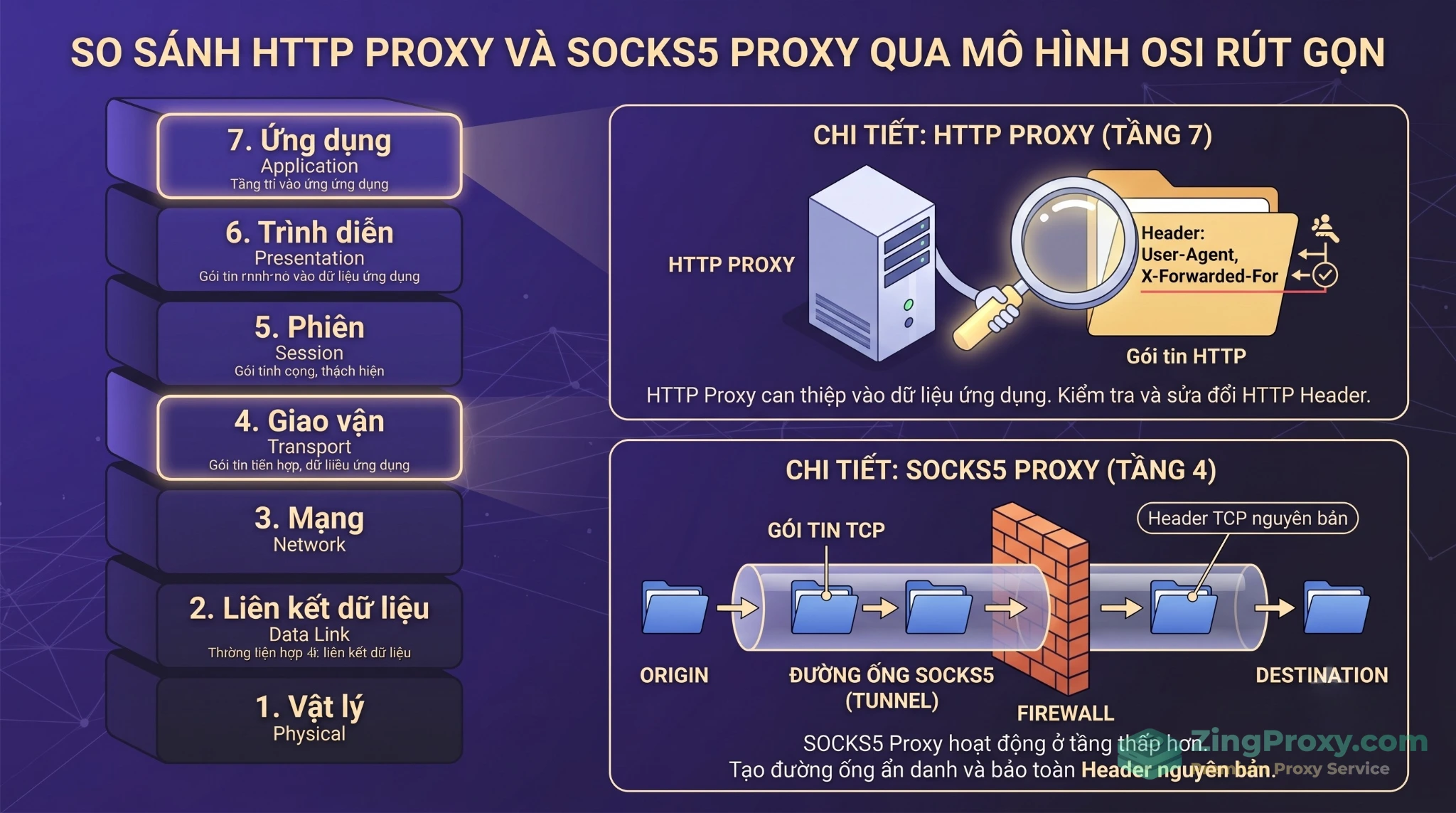
Theo kiến trúc mạng OSI, HTTP Proxy hoạt động ở Tầng 7 (Application Layer). Nó đọc, phân giải và có thể can thiệp vào HTTP Header. Điều này sinh ra độ trễ (overhead) không đáng có và dễ bị các hệ thống Anti-bot phát hiện do header bị chỉnh sửa.
Trong khi đó, SOCKS5 Proxy hoạt động ở Tầng 4 (Transport Layer). Nó đóng vai trò như một đường ống (tunnel) trong suốt. SOCKS5 nhận các gói tin TCP thô và đẩy nguyên vẹn đến server đích. Nó hoàn toàn không hiểu HTTP là gì, nên tuyệt đối không can thiệp vào Header của bạn (chẳng hạn như không tự ý thêm X-Forwarded-For). Nhờ đó, bạn giữ được độ an toàn và nguyên bản nhất cho request.
Bằng cách hoạt động ở tầng Giao vận (Layer 4), SOCKS5 Proxy đóng vai trò như một đường ống trong suốt, hoàn toàn không sửa đổi HTTP Header của Request.
Giải quyết bài toán đứt gãy pipeline nhờ cấu hình TCP Keep-Alive dài hạn
Lỗi ECONNRESET (Connection reset by peer) là vấn đề nan giải của nhiều Data Engineer. Nếu bạn thường xuyên đối mặt với thông báo này, hãy tìm hiểu thêm cách sửa lỗi ERR_PROXY_CONNECTION_FAILED cũng như hơn 10 lỗi mạng proxy phổ biến khác để tối ưu hóa hệ thống. Lỗi này xảy ra khi Client đẩy request vào một socket đã mất kết nối do sự lệch pha về thời gian Timeout giữa máy khách và máy chủ.
Mặc định của Node.js là đóng socket rảnh rỗi sau khoảng 5 giây. Nếu bạn dùng proxy mà không cấu hình Keep-Alive đồng bộ, proxy sẽ tưởng socket còn hoạt động, trong khi server đích đã ngắt kết nối. Giải pháp là thiết lập một luồng TCP dài hạn, dồn toàn bộ các request GraphQL nặng qua duy nhất một tunnel này, giúp giảm hoàn toàn thời gian bắt tay ba bước (3-way handshake) của TLS/SSL và giữ kết nối không bị vỡ.
Triển khai Scraper Client thực chiến với Node.js v26 & Native Fetch
Nếu bạn vẫn đang dùng CommonJS (require) và axios kết hợp với socks-proxy-agent để thu thập lượng lớn dữ liệu, đã đến lúc cập nhật giải pháp mới.
Từ Node.js v18 trở đi và đặc biệt tối ưu ở Node.js v26, Native Fetch API được trợ lực bởi engine Undici đã trở thành tiêu chuẩn mới. Undici mang lại throughput (thông lượng) cao gấp đôi, cấp phát bộ nhớ (Memory Allocation) thông minh hơn giúp giảm tải cho Garbage Collector (GC), và quản lý Connection Pooling cực kỳ xuất sắc.
Tạm biệt Axios: tối ưu Connection Pooling với Undici và fetch-socks
Chúng ta sẽ chuyển sang dùng ES Modules (import) và thư viện fetch-socks (hoặc cấu hình Dispatcher của Undici) để quản lý SOCKS5 proxy một cách triệt để.
import { socksDispatcher } from 'fetch-socks';
// 1. Setup Dispatcher (Agent thế hệ mới của Undici/Fetch)
// socksDispatcher tự động quản lý Connection Pooling và TCP Keep-Alive rất tối ưu
const proxyUrl = 'socks5://username:[email protected]:1080';
const dispatcher = socksDispatcher(proxyUrl, {
connect: {
timeout: 4000, // Timeout kết nối 4s: Chủ động dọn dẹp socket rảnh rỗi nhanh chóng
}
});
// 2. Viết hàm gọi GraphQL tái sử dụng dispatcher
async function fetchGraphQL(query, variables) {
const response = await fetch('https://api.example.com/graphql', {
method: 'POST',
dispatcher, // Gắn proxy SOCKS5 vào native fetch
headers: {
'Content-Type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...'
},
body: JSON.stringify({ query, variables })
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
}
Nguyên tắc vàng: Bằng cách set timeout: 4000 (4 giây) ở tầng kết nối, Client sẽ chủ động dọn dẹp các socket rảnh rỗi trước khi Server Node.js mặc định (5s) kịp ngắt kết nối chúng, từ đó xử lý triệt để lỗi ECONNRESET.
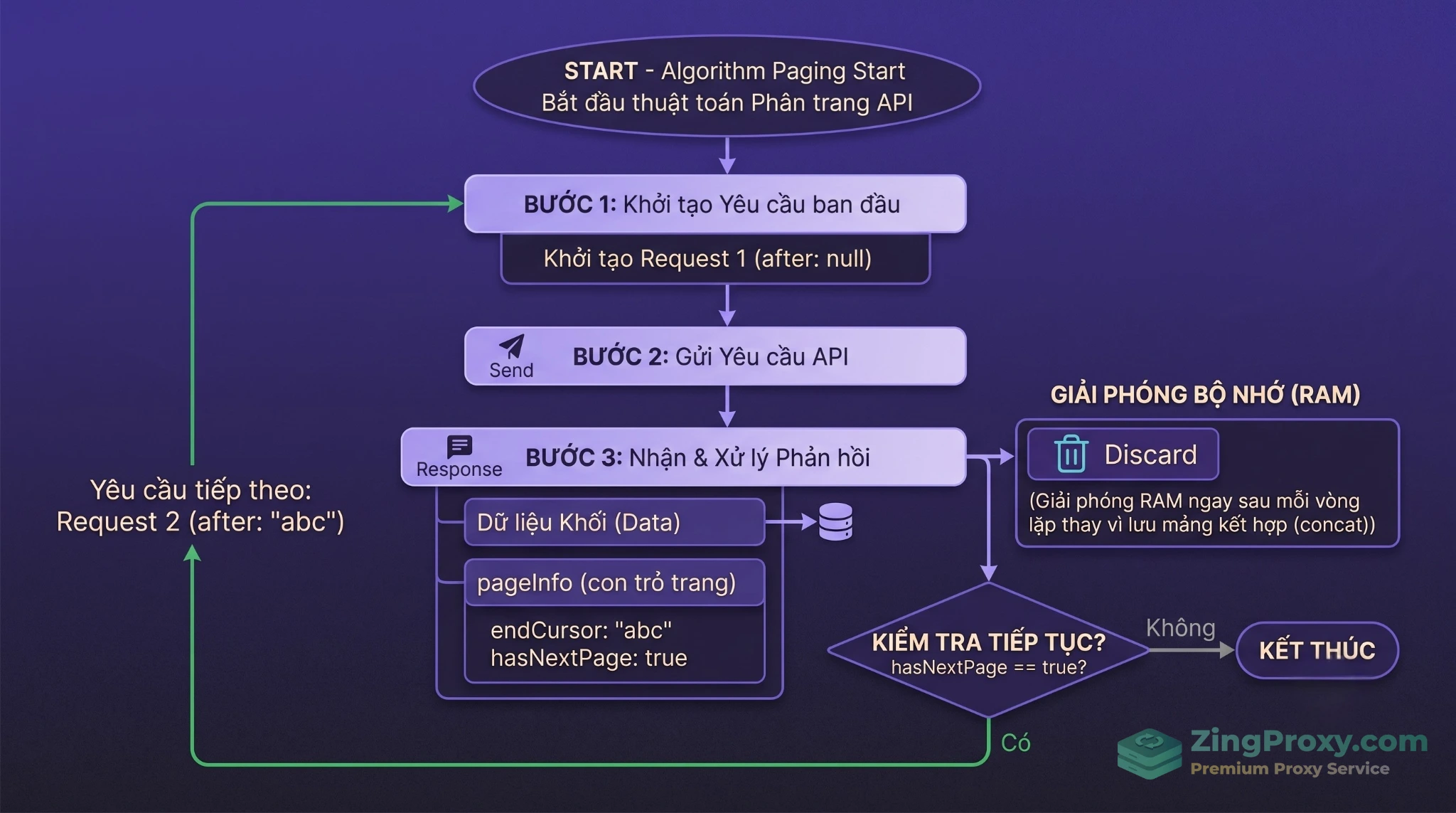
Xử lý triệt để bài toán Cursor-based Pagination đệ quy
Khác với REST API dùng page=1, page=2, tiêu chuẩn của GraphQL là phân trang theo con trỏ (Cursor-based Pagination).
Nhiều developer mới thường viết hàm đệ quy (recursion) để fetch toàn bộ các trang, sau đó array.concat() để gom dữ liệu lại. TUYỆT ĐỐI KHÔNG LÀM VẬY. Nếu kết quả trả về là 500,000 record, Call Stack sẽ phình to, Node.js sẽ lập tức báo lỗi Out Of Memory (tràn RAM OOM) và sập toàn bộ script.
Thay vào đó, hãy dùng vòng lặp while kết hợp chiến lược Process & Discard (Xử lý xong giải phóng ngay):
async function fetchAllRecords() {
let hasNextPage = true;
let cursor = null;
while (hasNextPage) {
const query = `
query GetData($cursor: String) {
records(first: 100, after: $cursor) {
edges { node { id title price } }
pageInfo { hasNextPage endCursor }
}
}
`;
// Gọi API qua Native Fetch + SOCKS5
const json = await fetchGraphQL(query, { cursor });
const data = json.data.records;
// 1. Process: Lưu thẳng vào Database, file, hoặc đẩy vào Message Queue
await saveToDatabase(data.edges.map(e => e.node));
// 2. Discard: Giải phóng mảng edges khỏi bộ nhớ, chuẩn bị cho vòng lặp sau
hasNextPage = data.pageInfo.hasNextPage;
cursor = data.pageInfo.endCursor;
}
}
Chiến lược Process & Discard với Cursor-based Pagination: Trích xuất endCursor để gọi trang tiếp theo và lập tức giải phóng bộ nhớ để tránh lỗi tràn RAM (OOM).
Xây dựng Data Pipeline bền vững và chịu tải cao
Khi scale up hệ thống, việc đẩy lượng lớn request lên server mà không kiểm soát là rủi ro lớn. Bạn cần xây dựng các cơ chế bảo vệ để Data Pipeline có thể duy trì hoạt động khi mất kết nối, và không nạp nhầm dữ liệu lỗi vào Data Warehouse.
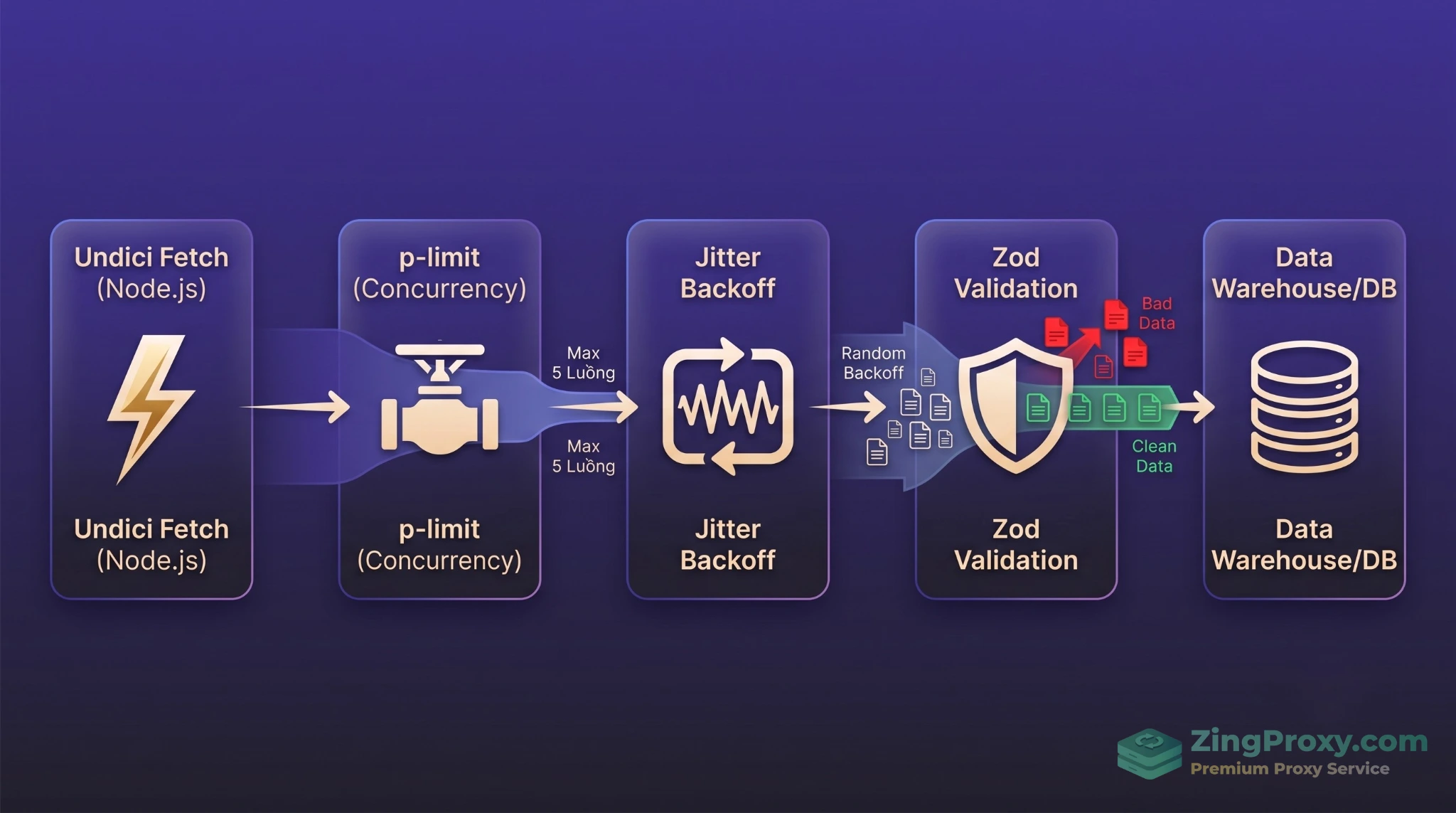
Quản lý Concurrency (p-limit) và Exponential Backoff với Jitter
Để tránh bị khóa IP, số lượng luồng chạy song song (concurrency) chỉ nên đặt ở mức gấp 3 đến 5 lần số lượng cổng proxy SOCKS5 bạn có. Chúng ta dùng thư viện p-limit để làm cơ chế điều tiết.
Đồng thời, khi máy chủ trả về mã 429 Too Many Requests, Client không được phép bỏ cuộc, nhưng cũng không được gửi lại request ngay lập tức. Phải dùng thuật toán Exponential Backoff (Lùi thời gian thích ứng).
Tuy nhiên, có một bẫy kỹ thuật cực kỳ nguy hiểm gọi là hiệu ứng Thundering Herd. Hãy tưởng tượng bạn có 50 luồng đồng loạt bị lỗi 429. Nếu bạn lập trình delay thuần túy Math.pow(2, attempt) * 1000, cả 50 luồng này sẽ đợi chính xác 4 giây, sau đó thức dậy cùng một mili-giây và tạo ra lượng tải đột biến lên server, khiến bạn lập tức bị chặn kết nối hoàn toàn. Để giải quyết, ta cần thêm yếu tố Jitter (độ nhiễu ngẫu nhiên).
import pLimit from 'p-limit';
const limit = pLimit(5); // Van điều tiết: max 5 request song song
async function fetchWithJitterBackoff(query, variables, attempt = 1, maxRetries = 5) {
try {
return await fetchGraphQL(query, variables);
} catch (error) {
if (error.message.includes('status: 429')) {
if (attempt > maxRetries) throw new Error('Max retries exceeded');
// Thêm Jitter để các request không thức dậy cùng lúc
const jitter = Math.floor(Math.random() * 500);
const delay = (Math.pow(2, attempt) * 1000) + jitter;
console.warn(`[Rate-limit] Luồng bị chặn. Chờ ${delay}ms trước khi thử lại... (Lần ${attempt})`);
await new Promise(r => setTimeout(r, delay));
return fetchWithJitterBackoff(query, variables, attempt + 1, maxRetries);
}
// Gặp lỗi mạng ngẫu nhiên (ECONNRESET từ proxy), thử lại ngay
if (error.cause && error.cause.code === 'ECONNRESET') {
return fetchWithJitterBackoff(query, variables, attempt, maxRetries);
}
throw error;
}
}
Đảm bảo Data Integrity với Zod Validation & Deduplication
Thu thập được dữ liệu đã khó, giữ cho dữ liệu an toàn và nhất quán còn khó hơn. GraphQL API đôi khi trả về null thay vì Array do lỗi nội bộ server, làm các hàm xử lý phía sau (như .map()) bị gián đoạn toàn bộ pipeline.
Đây là lúc thư viện Zod tối ưu hóa quy trình. Đóng vai trò là chốt chặn ở đầu vào, Zod cung cấp Validation Schema tĩnh, kiểm tra cấu trúc từng node trước khi đưa vào Database.
import { z } from 'zod';
// Định nghĩa khung xương (Schema) chuẩn mực
const ProductSchema = z.object({
id: z.string(),
title: z.string().min(1),
price: z.number().positive()
});
function processBatch(rawDataArray) {
rawDataArray.forEach(item => {
// safeParse không ném ra Error Exception làm sập script nếu data sai
const result = ProductSchema.safeParse(item);
if (result.success) {
// Dữ liệu đạt chuẩn, đẩy vào database (cần kết hợp Unique Constraint ở DB để Deduplication)
insertToDB(result.data);
} else {
// Bỏ qua bản ghi lỗi, lưu Dead Letter Queue để rà soát sau
console.error(`Bỏ qua bản ghi không hợp lệ. Lỗi:`, result.error.issues);
}
});
}
Nhờ safeParse(), dù API trả về dữ liệu lỗi cấu trúc, pipeline của bạn vẫn phân loại an toàn và tiếp tục duy trì hoạt động.
Kiến trúc Data Pipeline tiêu chuẩn: Điều tiết luồng bằng p-limit, quản lý retry bằng Jitter Backoff và kiểm soát chất lượng dữ liệu bằng Zod Validation.
Ethical Scraping & Best Practices an toàn
Việc tối ưu hạ tầng kỹ thuật là cần thiết, nhưng duy trì một tư duy lấy dữ liệu minh bạch mới giúp hệ thống của bạn tồn tại lâu dài:
Quản lý Header tự nhiên: Không nên gửi request với Header mặc định của Node. Hãy luân chuyển User-Agent dựa trên các trình duyệt thực tế. Proxy SOCKS5 hỗ trợ quản lý kết nối hiệu quả, nhưng Header thiếu tự nhiên sẽ khiến hệ thống nhận diện bạn là bot.
Tuân thủ Rate Limit và ToS: Luôn theo dõi các header như X-RateLimit-Remaining từ server. Nếu server báo hiệu bạn sắp vượt ngưỡng, hãy chủ động giảm tốc độ luồng. Không bao giờ gửi lượng request có nguy cơ tạo thành một cuộc tấn công từ chối dịch vụ.
Chỉ nhắm đến Dữ liệu công khai: Quá trình thu thập dữ liệu GraphQL nên tập trung vào dữ liệu public phục vụ nghiên cứu, phân tích thị trường. Tuyệt đối không khai thác lỗ hổng để trích xuất thông tin cá nhân (PII) vi phạm các quy định bảo mật.
Câu hỏi thường gặp (FAQ)
1. Tại sao Web Scraping GraphQL dễ bị Rate Limit?
Vì GraphQL giới hạn dựa trên Độ phức tạp truy vấn (Query Complexity), không đếm số lượng HTTP request. Một query lồng nhau (nested) quá sâu sẽ ngốn cạn băng thông máy chủ trong thời gian ngắn. Cách khắc phục: Làm phẳng (flatten) query, chia nhỏ request và giảm tham số limit.
2. Phải làm gì nếu server đích đã tắt tính năng Introspection?
Phải áp dụng Reverse Engineering thủ công. Cách khắc phục: Mở DevTools (F12) > Tab Network > Filter graphql. Bấm thao tác trên web và sao chép 3 thành phần operationName, query, variables từ thẻ Payload.
3. Nên dùng Axios hay Native Fetch cho Node.js v26?
Chắc chắn là Native Fetch. Lý do: Từ Node 18 trở lên (đặc biệt là v26), Native Fetch dùng engine Undici có thông lượng (throughput) cao hơn, tối ưu bộ nhớ và quản lý TCP Keep-Alive tốt hơn hẳn lõi HTTP cũ của Axios.
4. Cách sửa lỗi tràn RAM (OOM) khi thu thập dữ liệu GraphQL?
Bỏ ngay tư duy đệ quy và cộng dồn mảng (array.concat()). Cách khắc phục: Dùng vòng lặp while (hasNextPage). Áp dụng chiến lược Process & Discard: Lấy data trang nào -> Lưu thẳng vào Database trang đó -> Xóa biến mảng ngay lập tức để giải phóng RAM rồi mới gọi trang tiếp theo.
5. Dùng HTTP/HTTPS Proxy bình thường cào GraphQL được không?
Hoàn toàn được cho 90% tác vụ cơ bản. Lý do: Bạn chỉ bắt buộc dùng SOCKS5 khi cần luồng TCP Keep-Alive xuyên suốt cho file dữ liệu lớn, dùng WebSocket (GraphQL Subscriptions), hoặc cần duy trì 100% Header gốc không cho proxy can thiệp.
6. Tôi dùng SOCKS5 nhưng vẫn bị lỗi ECONNRESET, nguyên nhân do đâu?
Do cấu hình Timeout của bạn dài hơn mức chịu đựng của Server đích. Cách khắc phục: Node.js mặc định đóng socket sau 5 giây. Hãy chủ động hạ connect.timeout trên Client của bạn xuống mức 3-4 giây để tự dọn dẹp socket rảnh rỗi trước khi bị server ngắt kết nối.
7. Hệ thống bảo mật chặn quá khắt khe, tôi kết hợp SOCKS5 với Playwright được không?
Được, để vượt qua các lớp Anti-bot yêu cầu giải mã JavaScript. Lưu ý: Playwright đôi khi gặp trở ngại khi xác thực SOCKS5 bằng username:password. Tối ưu nhất là cấu hình IP Whitelist từ nhà cung cấp để kết nối trực tiếp.
Kết luận
Xử lý quy trình trích xuất GraphQL ở quy mô lớn yêu cầu kiến trúc hệ thống tối ưu hơn rất nhiều so với REST API. Bằng cách tận dụng Native Fetch với engine Undici của Node.js hiện đại, cấu hình SOCKS5 Dispatcher để duy trì TCP Keep-Alive, bạn có thể giải quyết triệt để vấn đề sập socket và tối ưu mức tiêu thụ RAM.
Hãy luôn nhớ trang bị cơ chế Exponential Backoff có cộng thêm Jitter để ứng phó với Rate Limit một cách an toàn, đồng thời thiết lập chốt chặn đầu vào bằng Zod để bảo vệ tính toàn vẹn của Data Warehouse.
Bạn setup một hệ thống thu thập dữ liệu hoạt động mượt mà cả đêm, đinh ninh sáng dậy sẽ có hàng triệu record hoàn chỉnh nằm gọn trong database. Thế nhưng, sáng mở log ra thì thấy dày đặc lỗi ECONNRESET hoặc dính hàng loạt mã 429 Too Many Requests. Nhìn kỹ lại thì […]
2 giờ sáng, hệ thống giám sát ping báo lỗi hàng loạt, màn hình hiển thị 502 Bad Gateway. Traffic spike chạm đỉnh, băng thông nghẽn cứng, proxy server từ chối mọi request. Trong lúc dầu sôi lửa bỏng, anh em Sysadmin vẫn phải hì hục SSH vào từng node, gõ lệnh tail -f đọc […]
Bạn đã bao giờ nhìn thấy pipeline GitHub Actions xanh rờn, test local pass 100%, hí hửng deploy lên Production rồi ngay lập tức nhận ticket report lỗi khẩn cấp từ user ở Nhật Bản vì trang thanh toán hiển thị USD thay vì JPY chưa? Hoặc một user ở Đức phàn nàn rằng họ […]
Đang thu thập dữ liệu mượt mà, pipeline chạy trơn tru, đột nhiên console đỏ rực một dải log: HTTP 429 Too Many Requests. Dữ liệu gãy nhịp, worker kẹt cứng, và tệ nhất là địa chỉ IP server chính thức mất kết nối. Đây chắc hẳn là kịch bản ám ảnh mà bất kỳ […]
Nhìn vào màn hình console với chỉ số CPU chạm nóc 100%, RAM cạn kiệt và MySQL liên tục báo lỗi Too many connections là cơn ác mộng kinh điển của bất kỳ developer hay sysadmin nào. Khi một bài viết trên WordPress bất ngờ viral hoặc hệ thống chạy chiến dịch quảng cáo lớn, […]
Tám giờ tối, bạn vừa deploy xong một tính năng cực mượt có tích hợp AI. Nhưng khi lượng user bắt đầu tăng lên, log trên backend liên tục báo lỗi với những dòng chữ đỏ: ECONNRESET, ETIMEDOUT, hoặc các luồng Server-Sent Events (SSE) đang stream dở văn bản thì đột ngột bị ngắt kết […]