Ứng dụng đang chạy mượt mà ở môi trường local bỗng chốc đổ sập khi đẩy lên production vì hàng loạt lỗi HTTP 429 Too Many Requests (đây cũng là một trong những mã lỗi Proxy phổ biến nhất thường gặp khi scale ứng dụng). Các worker queue bị nghẽn, thời gian chờ phản hồi (latency) tăng vọt, và đau đớn nhất là hóa đơn API cuối tháng tăng phi mã vì cơ chế Context Caching giá rẻ đột nhiên bị vô hiệu hóa. Đây là nỗi đau chung của hàng ngàn AI Engineer và Backend Developer khi phải scale hệ thống tích hợp các LLM lớn.
Nhiều team cố gắng giải quyết bằng cách mua thêm hàng tá API Key và dùng các bộ cân bằng tải cơ bản. Tuy nhiên, nếu luồng gọi API không được thiết kế để hiểu ngữ nghĩa của token và cơ chế bộ nhớ đệm, bạn đang tự tạo ra một nút thắt cổ chai khổng lồ. Để xử lý dứt điểm bài toán rớt kết nối và tối ưu chi phí hạ tầng, việc thiết lập một reverse proxy phân tải API chuyên dụng cho LLM là điều kiện bắt buộc.
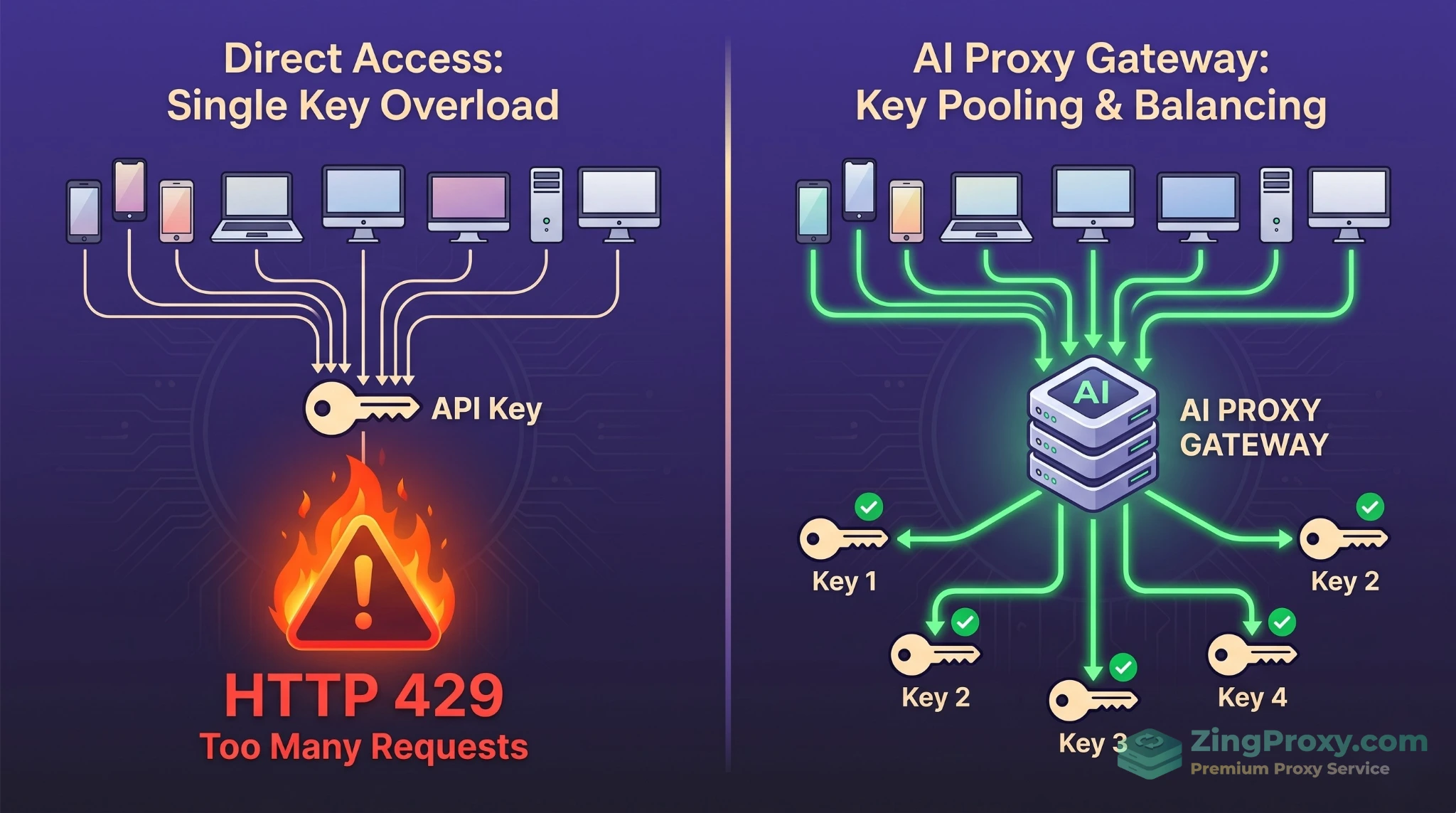
Sự khác biệt giữa truy cập trực tiếp gây lỗi 429 (trái) và hệ thống phân tải thông minh qua Proxy (phải).
Nếu bạn chưa nắm rõ khái niệm nền tảng, hãy tham khảo bài viết giải thích chi tiết Proxy ngược là gì và các trường hợp sử dụng Proxy ngược.
Nỗi ám ảnh Rate Limit và Timeout khi scale hệ thống AI
Khi bạn đẩy các ngữ cảnh dài (long context), cụ thể là 1M token đối với DeepSeek V4 và 256K token đối với Kimi 2.6 vào hệ thống, các giới hạn của nhà cung cấp sẽ lập tức siết chặt pipeline của bạn.
Nút thắt Concurrency: DeepSeek V4 và Kimi 2.6
Mỗi nhà cung cấp có một chiến lược phòng thủ hạ tầng riêng, và nếu không hiểu rõ, ứng dụng của bạn sẽ liên tục bị giới hạn băng thông:
- Kimi K2.6 (Giới hạn cứng theo Tier): Hệ thống của Moonshot AI áp dụng giới hạn tác vụ đồng thời (Concurrent Tasks) cực kỳ khắt khe dựa trên cấp độ thành viên. Nếu dùng gói Adagio (Miễn phí), bạn chỉ có đúng 1 tác vụ đồng thời. Nâng cấp lên Moderato ($15) hoặc Allegretto ($31), giới hạn là 2 tác vụ. Ngay cả ở gói cao cấp Allegro ($79) hoặc Vivace ($159), bạn cũng chỉ được cấp phép tối đa 4 tác vụ đồng thời. Nếu dùng API dạng Pay-As-You-Go, giới hạn này sẽ mở dần từ 1 (Tier 0) lên tối đa 1.000 (Tier 5) dựa trên tổng tiền đã nạp. Khi bạn gửi ngữ cảnh 256K, ngân sách TPM (Tokens Per Minute) cũng sẽ bốc hơi chỉ sau vài request.
- DeepSeek V4 (Kiểm soát đồng thời động): Dù nổi tiếng với khả năng xử lý khối lượng lớn, DeepSeek lại áp dụng cơ chế Dynamic Concurrency dựa trên tải thực tế của server. Khi peak traffic, bạn sẽ lập tức nhận lỗi HTTP 429 dù chưa chạm trần TPM. Hơn nữa, với các context dài tốn nhiều thời gian đọc hiểu, nếu máy chủ không thể bắt đầu quá trình suy luận (inference) trong vòng 10 phút, DeepSeek sẽ chủ động ngắt kết nối (timeout).
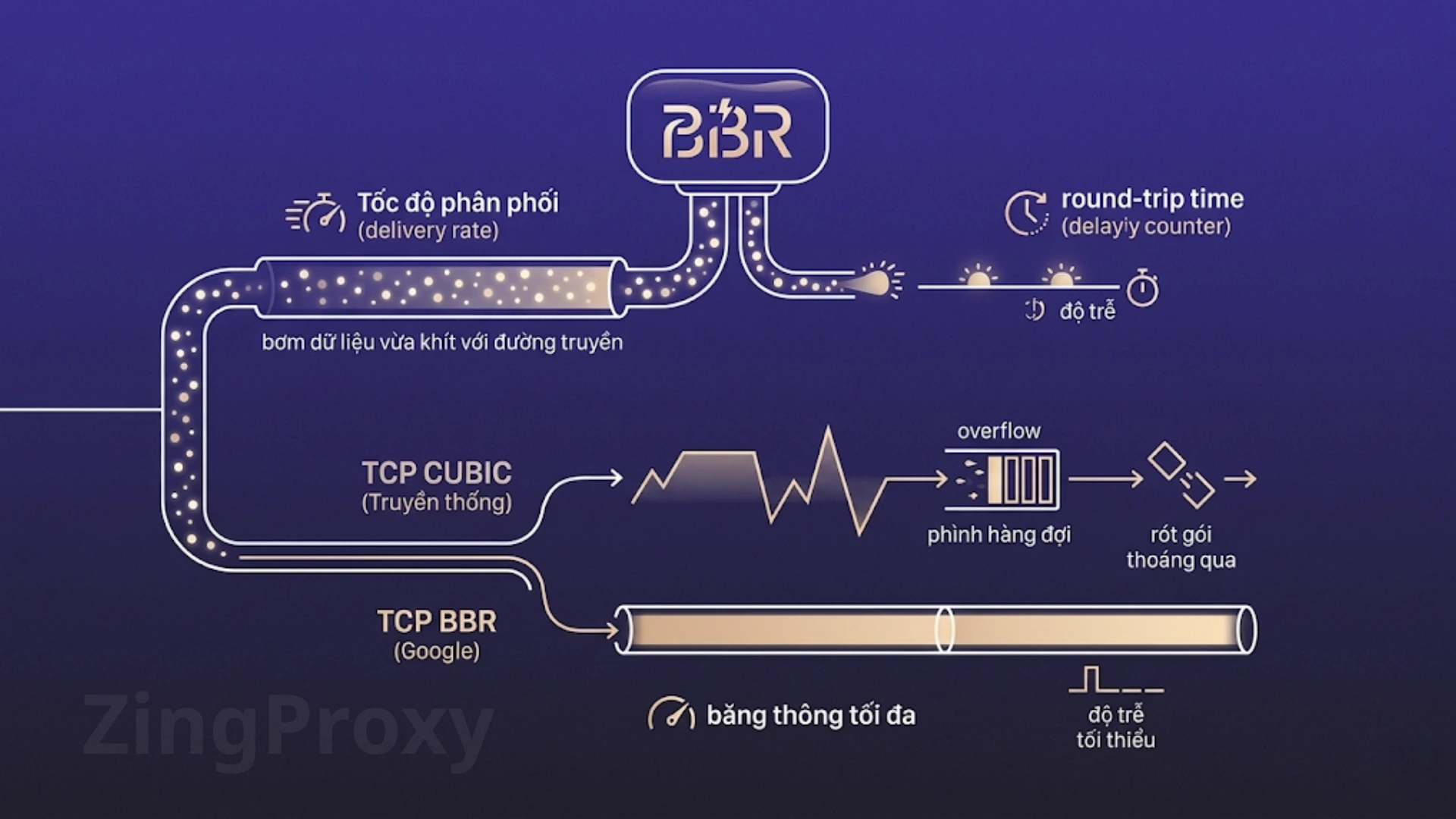
Bẫy Load Balancing Round-Robin làm vỡ Context Caching
Nhận thấy sự gò bó của 1 API Key, phản xạ tự nhiên của developer là gom nhiều Key lại và dùng thuật toán Round-Robin (phân phối luân phiên) để cân bằng tải. Tuy nhiên, điều này tạo ra sự xung đột trực tiếp với tính cô lập dữ liệu của LLM, làm vỡ hoàn toàn Context Caching.
Các nhà cung cấp thiết kế bộ nhớ đệm (Cache) bị cô lập hoàn toàn theo từng API Key để bảo mật. Hãy hình dung luồng sau:
- Bạn gửi 1 System Prompt dài 50K token. Load Balancer đẩy request vào API Key A. Dữ liệu được lưu vào cache của Key A.
- User gửi câu hỏi tiếp theo dựa trên đoạn hội thoại đó. Round-Robin luân chuyển request này sang API Key B.
- Cache Miss: Vì Key B không thể đọc cache của Key A, LLM phải đọc lại 50K token từ con số 0.
Hậu quả là một thảm họa về hiệu năng và chi phí:
- Độ trễ (Latency): Thay vì token đầu tiên được xuất ra trong 500ms (nhờ hit cache), hệ thống có thể mất đến 13 giây để đọc lại dữ liệu.
- Đội chi phí: Lấy bảng giá DeepSeek V4 (cập nhật mới nhất) làm ví dụ. Với mô hình
deepseek-v4-flash, nếu Miss Cache, giá vọt lên $0.14/1M token. Nhưng nếu Hit Cache, bạn chỉ trả mức giá sập sàn $0.0028/1M token (rẻ hơn 50 lần). Tương tự, với mô hình deepseek-v4-pro (đang giảm giá 75%), chi phí Hit Cache chạm đáy chỉ còn $0.003625/1M token. Việc dùng Round-Robin đã ném khoản tiết kiệm khổng lồ này qua cửa sổ.
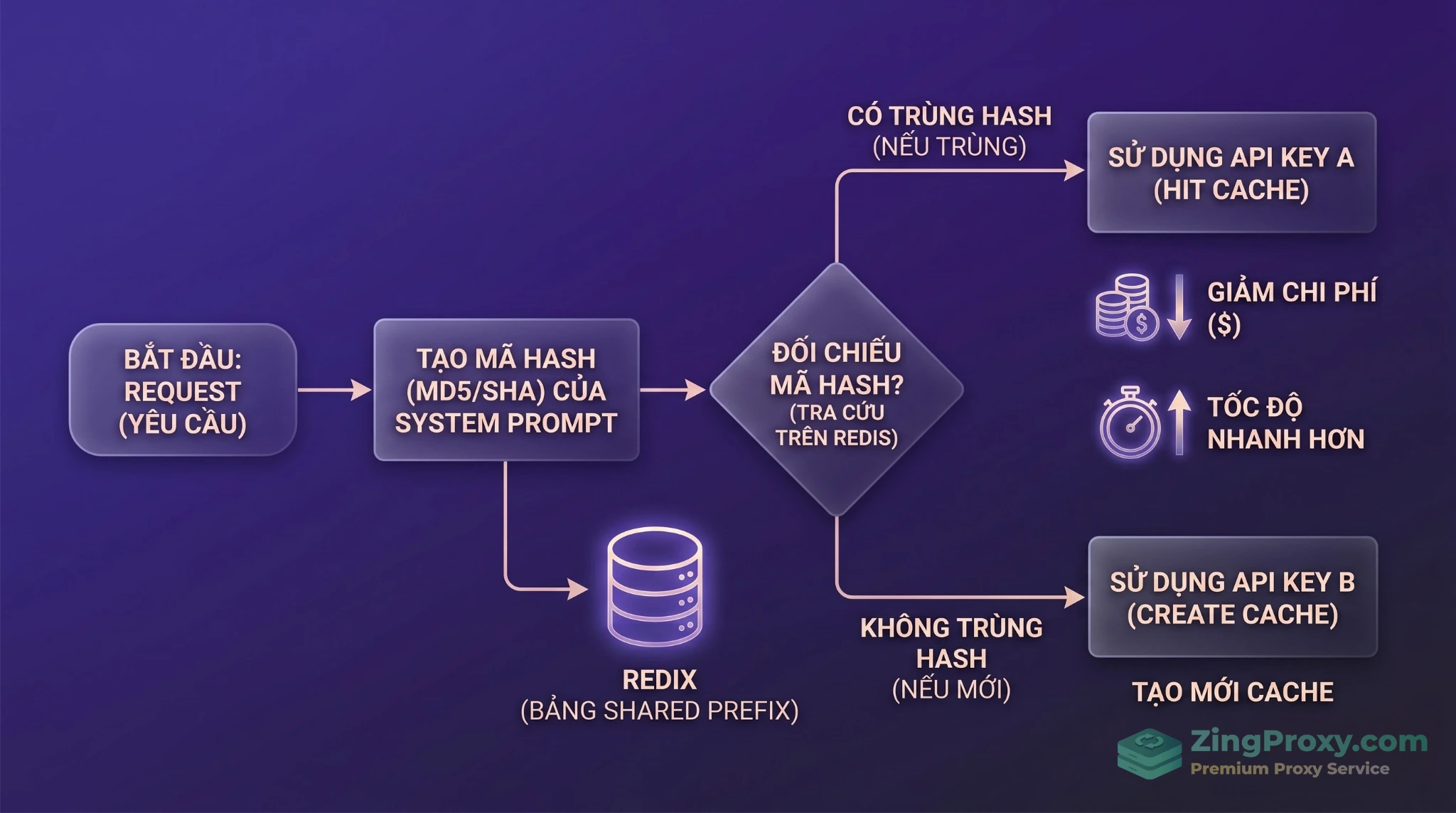
Cơ chế Hashing System Prompt giúp duy trì tỷ lệ Cache Hit tối đa, giảm chi phí đầu vào xuống mức $0.0028/1M token.
Giải phẫu kiến trúc Reverse Proxy phân tải API: Chuyện gì xảy ra trong 50ms?
Nhiều người e ngại đặt một lớp proxy ở giữa sẽ làm chậm tốc độ phản hồi. Thực tế, tổng thời gian trễ (latency overhead) khi một request đi qua LLM Proxy (như kiến trúc của Preto.ai) chỉ chiếm dưới 50 mili-giây (ms), thường dao động từ 7-25ms. Mức này chưa tới 3% tổng thời gian sinh text của LLM.
Để hệ thống không bao giờ rớt nhịp, bạn nên cân nhắc triển khai kiến trúc High Availability Proxy và thiết lập tự động failover để đạt uptime 99.9%.
7 lớp xử lý tối ưu không làm chậm luồng suy luận
Bên trong lớp proxy, request của bạn sẽ đi qua 7 chốt chặn với tốc độ tính bằng mili-giây:
- Ingress & Auth (~2-5ms): Tiếp nhận HTTP và xác thực danh tính nội bộ để ẩn đi API Key gốc.
- Rate Limiting Check (~1-3ms): Kiểm tra TPM/RPM và ngân sách (chạy in-memory cực nhanh).
- Cache Lookup (~1-8ms): Băm (hash) prompt để kiểm tra xem ngữ nghĩa này đã từng được xử lý chưa.
- Key Rotation & Routing (~1-3ms): Đưa ra quyết định định tuyến thông minh (tránh dùng Round-Robin).
- Upstream Call (~500ms – 5,000ms): Thời gian thực tế gọi API lên DeepSeek/Kimi. Token được stream thẳng về client.
- Error Handling & Fallback (~0ms): Nếu API thành công, tốn 0ms. Nếu dính lỗi 429/503, proxy tốn khoảng 100-500ms để kích hoạt thử lại hoặc đổi mô hình.
- Logging & Cost Attribution (~2-5ms): Tính tiền token tiêu thụ và ghi log metadata. Luồng này chạy bất đồng bộ (async) nên không hề block phản hồi của người dùng.
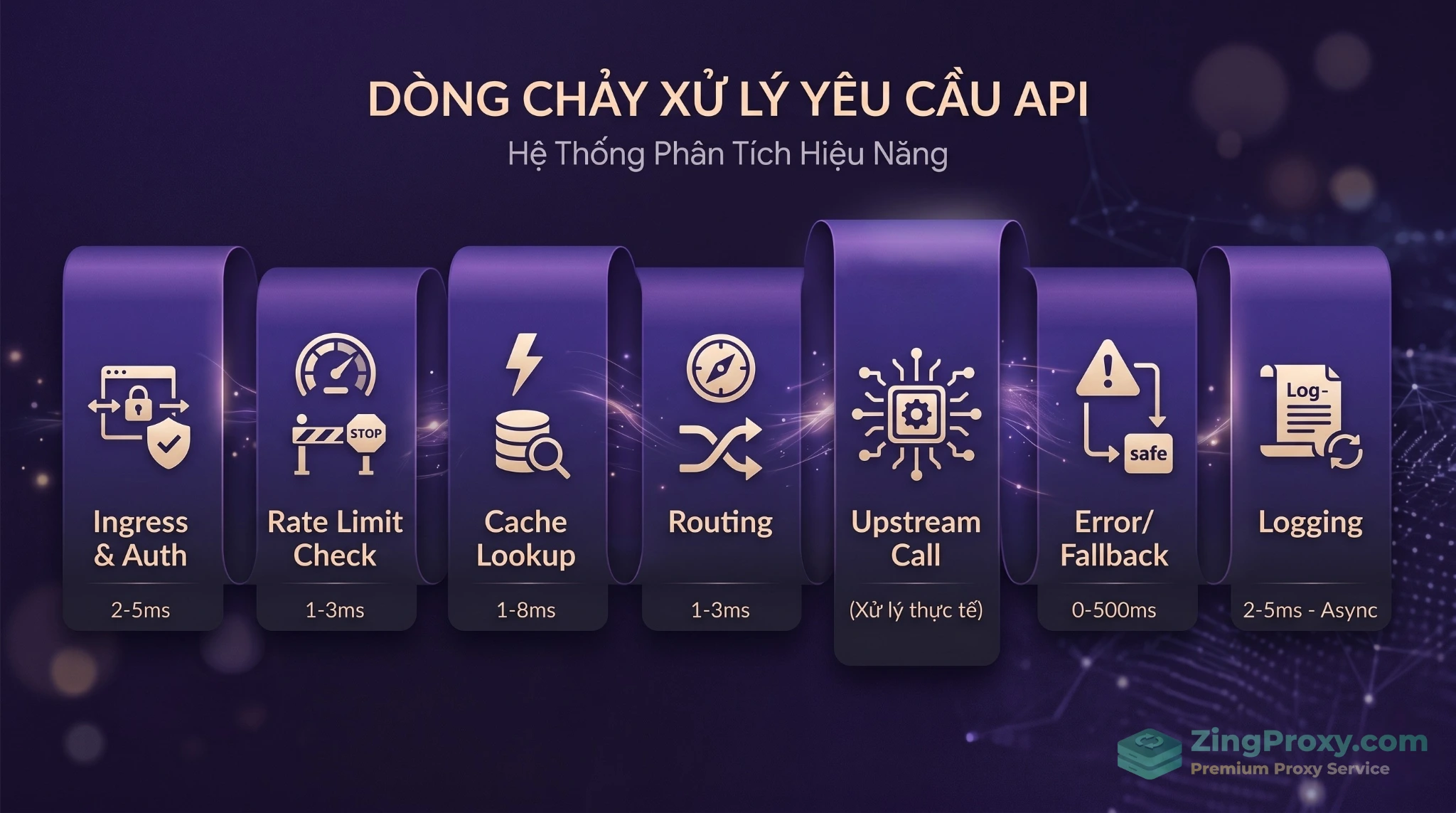
Tổng độ trễ overhead của Proxy chỉ chiếm khoảng 25-50ms, không đáng kể so với lợi ích bảo vệ hạ tầng.
Nguyên lý Cache-Aware Routing: Phép màu giữ Cache Hit 90-100%
Để khắc phục yếu điểm của Round-Robin, các proxy hiện đại sử dụng chiến lược Shared Prefix Routing (Định tuyến chia sẻ tiền tố). Thay vì phân phối mù quáng, proxy sẽ phân tích body JSON, đọc tiền tố (prefix) của prompt và đẩy request về đúng API Key/Worker đang giữ KV Cache của đoạn tiền tố đó.
Kiến trúc này hoạt động dựa trên 3 trụ cột kỹ thuật:
- Cây Radix (Radix Tree): Bộ định tuyến duy trì một cây Radix cục bộ với độ phức tạp O(prefix_length) để theo dõi chính xác worker nào đang nắm giữ KV cache. Quá trình đọc không cần khóa (lock-free) diễn ra siêu tốc.
- Shared Prefix Table qua Redis: Để phá vỡ giới hạn phân mảnh của Load Balancer, các node proxy dùng chung một bảng tiền tố trên Redis. Tất cả proxy đều chung một kho kiến thức, nâng tỷ lệ Hit Cache lên tiệm cận 100%. Các lệnh cập nhật lên Redis dùng cơ chế ghi xác suất (Probabilistic Writes) khoảng 10% để chống quá tải.
- Token ID Cache: Để tiết kiệm 100ms thời gian LLM phải tokenize lại các đoạn prompt quen thuộc, proxy tính toán và lưu sẵn Token ID, giảm độ trễ bước này xuống dưới 1ms.
Lựa chọn Tech Stack: LLM-Aware Gateway hay NGINX thuần?
Việc tự phát minh lại bánh xe để phân tích JSON payload của LLM là một sai lầm tốn kém (thường mất 6-12 tháng của team kỹ sư). Hãy chọn đúng công cụ cho bài toán của bạn.
LiteLLM & New API / Chat2API (khuyên dùng)
Đây là các giải pháp LLM-Aware (nhận thức được LLM), lý tưởng cho AI Engineer:
- Chuẩn hóa API (Universal API): Biến mọi endpoint của Claude, Gemini, Kimi, DeepSeek về chuẩn OpenAI.
- Định tuyến thông minh: Hỗ trợ định tuyến theo giá (cost-based), theo độ trễ (latency-based) và tự động Fallback.
- Cung cấp sẵn cơ chế theo dõi Token Budgets, giao diện quản trị UI xịn xò (như của New API).
- Nhược điểm: Tốn thêm vài chục ms overhead do phải parse body JSON, và phụ thuộc cập nhật từ cộng đồng mã nguồn mở.
Tự build bằng NGINX + Lua/OpenResty
Nếu bạn cần một hệ thống xử lý từ 10.000 đến 1.000.000 kết nối đồng thời với độ trễ I/O bằng 0, NGINX + Lua là giải pháp tối ưu.
- Sức mạnh: Sử dụng thuật toán Leaky Bucket cực mạnh để Rate Limit, kiểm soát toàn diện HTTP header.
- Nhược điểm chí mạng: NGINX không hiểu LLM, nó đánh đồng một request 50 token và 128K token như nhau. Đặc biệt, NGINX mặc định bật gom bộ đệm (
proxy_buffering on). Điều này sẽ giết chết hoàn toàn tính năng Streaming của LLM (NDJSON/SSE). Bạn bắt buộc phải tắt buffering, tăng timeout và ép dùng HTTP/1.1 bằng script Lua rất phức tạp.
Bảng so sánh LiteLLM & New API vs NGINX thuần
| Tiêu chí |
LiteLLM & New API (Giải pháp LLM-Aware) |
NGINX + Lua (Giải pháp LLM-Agnostic) |
| Đặc tính |
Hiểu LLM (Phân tích JSON payload và Token). |
Proxy mạng thuần túy (Chỉ xử lý gói tin HTTP/TCP). |
| Độ trễ (Overhead) |
Thêm khoảng ~10-25ms (Do parse JSON). |
Gần như 0ms (Xử lý I/O siêu tốc). |
| Quản lý Rate Limit |
Theo số Token (TPM) & Ngân sách chi tiêu ($). |
Theo số Request (RPM/RPS). |
| Điểm nổi bật |
Smart Routing, Fallback tự động, có sẵn UI/Dashboard. |
Chịu tải mạng siêu việt (hàng trăm ngàn RPS). |
| Nhược điểm chí mạng |
Phụ thuộc tốc độ update của cộng đồng mã nguồn mở. |
Mặc định làm hỏng tính năng Streaming (nếu không cấu hình tắt buffering). |
| Đối tượng phù hợp |
AI Engineer cần deploy nhanh, bảo vệ ngân sách. |
DevOps/Sysadmin cần kiểm soát luồng traffic thô. |
3 kỹ thuật sống còn khi triển khai trên Production
Triển khai xong proxy chưa phải là điểm kết thúc. Để hệ thống hoạt động bền bỉ trên production, bạn cần 3 kỹ thuật sau.
Đồng bộ Multi-node bằng Redis (và mẹo kết hợp In-memory)
Khi scale hạ tầng trên Kubernetes, bạn sẽ có nhiều Pod chạy proxy. Nếu chỉ lưu giới hạn TPM (Tokens Per Minute) trên bộ nhớ RAM (in-memory) của từng Pod, bạn sẽ gặp thảm họa. Ví dụ: Cấu hình giới hạn 10.000 TPM, nhưng có 3 Pod độc lập -> Hệ thống vô tình đẩy ngưỡng lên 30.000 TPM và bị provider ban API Key.
Bắt buộc phải dùng Redis để làm nguồn sự thật duy nhất (Single Source of Truth), đảm bảo:
- Đồng bộ Rate Limit toàn cục giữa các instance.
- Chia sẻ trạng thái “Cooldown” (Khi Node A nhận lỗi 429, Node B cũng biết để ngưng gọi vào Key đó).
- Đảm bảo tính phi trạng thái (Stateless) để Auto Scaling an toàn.
Mẹo thực chiến: Để tránh độ trễ mạng khi gọi Redis liên tục, các proxy như LiteLLM dùng bộ nhớ in-memory cục bộ để bắt request siêu tốc, nhưng đồng bộ hóa nền với Redis định kỳ 0.01 giây/lần. Kỹ thuật này giúp proxy phản hồi nhanh gấp 2 lần mà độ lệch dữ liệu (drift) không quá 10 request.
Chống hiệu ứng đàn trâu (Retry Storm) với Exponential Backoff
Khi chạm Rate Limit, DeepSeek/Kimi sẽ trả lỗi 429. Phản xạ của các thư viện HTTP client thông thường là lập tức retry lại. Hàng ngàn client cùng retry sẽ tạo ra sự khuếch đại thử lại (retry amplification), tạo thành hiệu ứng Đàn trâu. Lưu lượng rác bùng nổ, đẩy thời gian chờ (cool-down) lên 400%, làm sập luôn SLA của hệ thống.
Giải pháp tiêu chuẩn:
- Đọc header
Retry-After: Provider thường gửi kèm header báo rõ số giây cần chờ. Hãy tuân thủ tuyệt đối con số này bằng lệnh sleep.
- Exponential Backoff with Jitter: Nếu không có
Retry-After, proxy phải áp dụng lùi bước theo cấp số nhân (đợi 1s, 2s, 4s…). Quan trọng nhất là phải cộng thêm Jitter (độ lệch ngẫu nhiên) vào thời gian chờ. Jitter giúp dàn đều thời điểm thức dậy của hàng ngàn client, triệt tiêu hoàn toàn sự hội tụ lưu lượng.
- Lưu ý: Chỉ cho phép retry tối đa 3-5 lần, và chỉ áp dụng với các request có tính lũy đẳng (idempotent).
Cấu hình Token Budgets làm phanh khẩn cấp cho AI Agent
Trong kiến trúc Agentic AI, các Agent tự động suy luận và gọi Tool (Tool calling). Chuyện gì xảy ra nếu Agent gặp lỗi logic và rơi vào một vòng lặp vô hạn (infinite loop), liên tục nhồi context 256K vào LLM? Nó sẽ đốt sạch vài trăm USD của bạn chỉ trong 1 đêm.
Cơ chế Token Budgets (Ngân sách Token) của proxy sinh ra để làm phanh khẩn cấp ở cấp độ phiên (session-level caps). Bằng cách kích hoạt require_trace_id_on_calls_by_agent, bạn có thể giới hạn:
max_iterations: Số vòng lặp gọi API tối đa trong một phiên.max_budget_per_session: Số tiền tối đa (VD: $1) cho một chuỗi tác vụ.session_tpm_limit: Giới hạn tốc độ đốt token trong một session.
Khi Agent bị kẹt và chạm ngưỡng ngân sách này, proxy lập tức cắt đứt kết nối và trả về lỗi giả lập “429 Too Many Requests” hoặc 403, cứu tài khoản của bạn khỏi bị bòn rút.

Hai tính năng “sống còn” giúp bảo vệ IP khỏi bị ban và ngăn chặn thảm họa đốt tiền do lỗi logic của AI Agent.
Nếu bạn đang thiết kế hệ thống tương tự, việc tìm hiểu cách tối ưu hạ tầng AI Agent bằng phương pháp phân tải request mượt mà qua Proxy dân cư xoay vòng sẽ cung cấp thêm góc nhìn toàn diện.
Giám sát hệ thống: Đọc đúng chỉ số Cache Hit
Bạn cấu hình Shared Prefix Routing xong, làm sao để biết nó có hoạt động? Đừng đoán mò.
Trong dữ liệu JSON Response trả về từ DeepSeek API, hãy chú ý đến khối usage. DeepSeek cung cấp chính xác hai trường:
prompt_cache_hit_tokens: Số lượng token ngữ cảnh đã được lôi ra từ bộ nhớ đệm thành công.prompt_cache_miss_tokens: Số lượng token phải chạy suy luận lại từ đầu.
Đưa hai metrics này lên Grafana Dashboard. Nếu tỷ lệ Hit rớt xuống dưới 80%, hãy kiểm tra lại code backend xem có ai đó vô tình chèn biến động (như Timestamp, UserID) vào đầu System Prompt hay không.
Để nắm rõ quy trình thu thập và trực quan hóa dữ liệu log này, mời bạn tham khảo tài liệu hướng dẫn về cách giám sát traffic Proxy Server theo thời gian thực.
Câu hỏi thường gặp (FAQ)
1. Nguyên nhân chính gây lỗi HTTP 429 trên DeepSeek V4 là gì?
Do hệ thống kiểm soát kết nối đồng thời động (Dynamic Concurrency) dựa trên tải của server và việc vượt ngưỡng Token mỗi phút (TPM). Lỗi này xảy ra dày đặc hơn khi bạn gửi Context dài mà không tận dụng được bộ nhớ đệm (Cache Miss).
2. Reverse proxy ảnh hưởng thế nào đến độ trễ (Latency) của AI API?
Ảnh hưởng cực thấp. Một proxy tối ưu chỉ thêm khoảng 7-25ms (overhead <3%). Tuy nhiên, nó giúp tăng tốc độ gấp 20 lần (giảm từ 13s xuống 500ms) nếu request trúng Cache nhờ kỹ thuật định tuyến thông minh.
3. Tôi có bắt buộc phải cài đặt Redis khi thiết lập Reverse Proxy không?
Bắt buộc nếu bạn chạy trên nhiều máy chủ (Multi-node) hoặc Kubernetes. Redis đóng vai trò bộ não trung tâm để đồng bộ hóa hạn mức Token (TPM/RPM) và trạng thái API Key, tránh việc các node chạy lệch pha dẫn đến bị provider khóa Key.
4. Làm sao để biết hệ thống phân tải API đang hoạt động hiệu quả?
Kiểm tra trường prompt_cache_hit_tokens trong phần usage của JSON response. Nếu tỷ lệ này duy trì trên 80%, nghĩa là Proxy của bạn đang định tuyến cực tốt và bạn đang tiết kiệm được tới 90% chi phí API.
5. Token Budgets bảo vệ tài khoản AI Agent khỏi vòng lặp vô hạn như thế nào?
Hoạt động như một phanh khẩn cấp. Proxy sẽ theo dõi Metadata của phiên làm việc và lập tức ngắt kết nối (Circuit Breaker) nếu phát hiện Agent tiêu thụ vượt quá số tiền hoặc số vòng lặp quy định cho mỗi tác vụ.
Tài liệu tham khảo