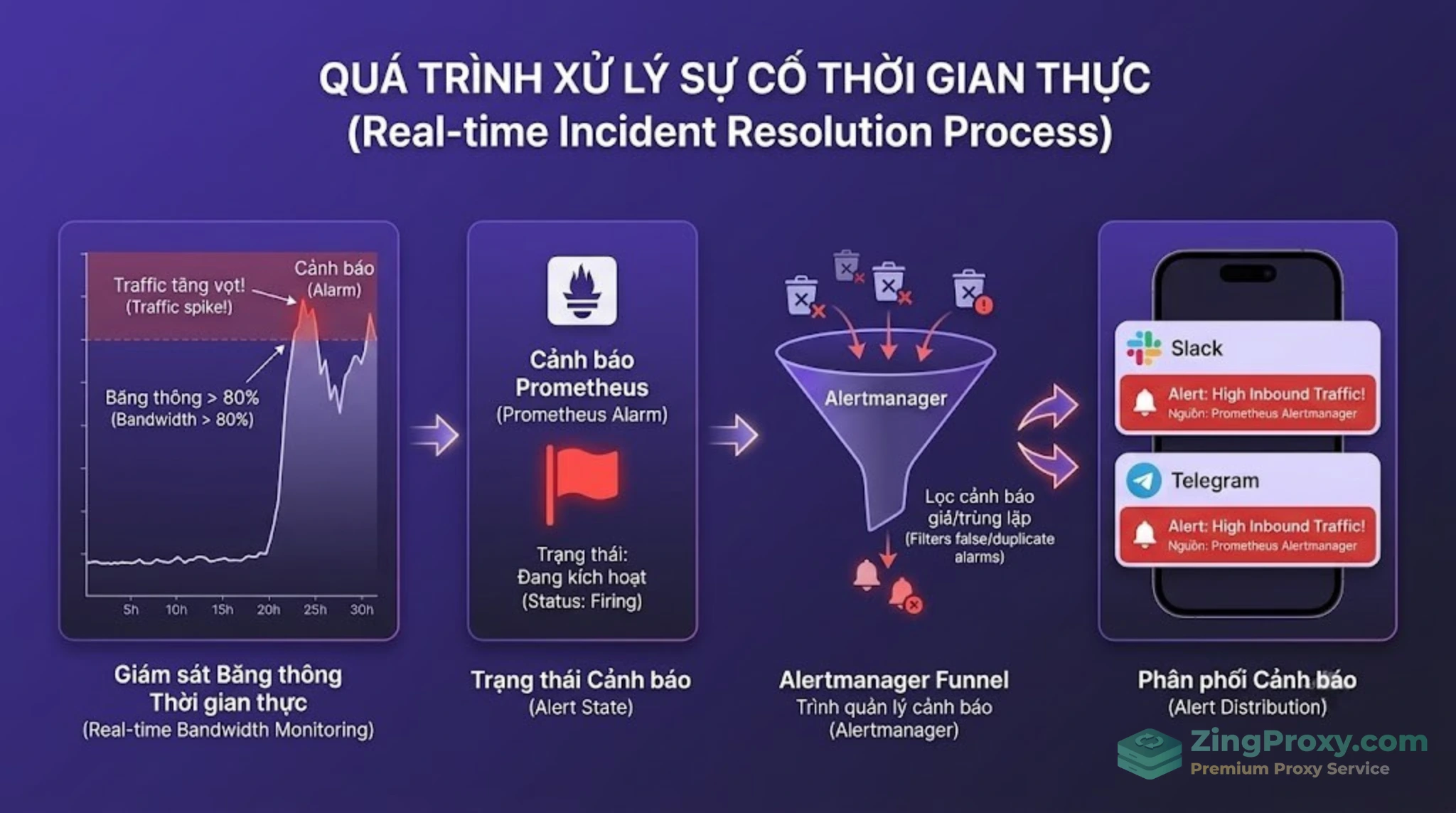
2 giờ sáng, hệ thống giám sát ping báo lỗi hàng loạt, màn hình hiển thị 502 Bad Gateway. Traffic spike chạm đỉnh, băng thông nghẽn cứng, proxy server từ chối mọi request. Trong lúc dầu sôi lửa bỏng, anh em Sysadmin vẫn phải hì hục SSH vào từng node, gõ lệnh tail -f đọc log thủ công hoặc dùng vnstat để mò mẫm xem IP nào đang spam. Đến khi tìm ra thủ phạm thì server cũng đã ngừng hoạt động từ lâu, kéo theo trải nghiệm người dùng chạm đáy.
Đã đến lúc chúng ta cần từ bỏ việc monitor chạy bằng cơm. Để bắt bệnh hạ tầng ngay từ khi có dấu hiệu bất thường đầu tiên, việc triển khai một hệ thống giám sát Proxy Grafana kết hợp với sức mạnh của Prometheus là tiêu chuẩn Observability (khả năng quan sát) bắt buộc.
Vậy làm thế nào để deploy một stack tracking time-series metrics realtime, chịu tải hàng triệu request mà không làm phình to I/O của server hiện tại? Cùng giải phẫu chi tiết kiến trúc monitor chuẩn Enterprise ngay dưới đây nhé!
Từ bỏ monitor chạy bằng cơm: Lợi thế của kiến trúc Time-Series
Khi hạ tầng scale lên từ vài node đến hàng chục Proxy server, các công cụ quản trị truyền thống bộc lộ rõ điểm yếu chí mạng.
Sự bất lực của công cụ truyền thống khi scale hạ tầng
Việc giám sát băng thông yêu cầu hệ thống phải liên tục ghi nhận hàng ngàn metric (số liệu mạng) mỗi giây. Nếu bạn cố gắng nhồi nhét lượng log này vào một hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) như MySQL, khối lượng dữ liệu khổng lồ đổ về liên tục sẽ ngay lập tức gây ra tình trạng nghẽn cổ chai I/O (I/O Bottleneck).
RDBMS đơn giản là không được sinh ra để ghi dữ liệu với tần suất cao như vậy. Thêm vào đó, các tool như netstat hay vnstat chỉ cho bạn con số của hiện tại, hoàn toàn không có khả năng đối chiếu lịch sử để tìm ra pattern của một cuộc tấn công mạng hoặc đợt tăng tải đột biến.
Sức mạnh của Time-Series Database (TSDB) và cơ chế Pull-model
Prometheus giải quyết bài toán này bằng Time-Series Database (TSDB) chuyên biệt. Dữ liệu được ghi qua bộ nhớ và cơ chế Write-Ahead Log (WAL) hoạt động theo nguyên lý append-only logs (chỉ ghi nối thêm). Không có random writes, không có độ trễ ổ cứng, Prometheus có thể xử lý hàng triệu mẫu dữ liệu mỗi giây cực kỳ mượt mà.
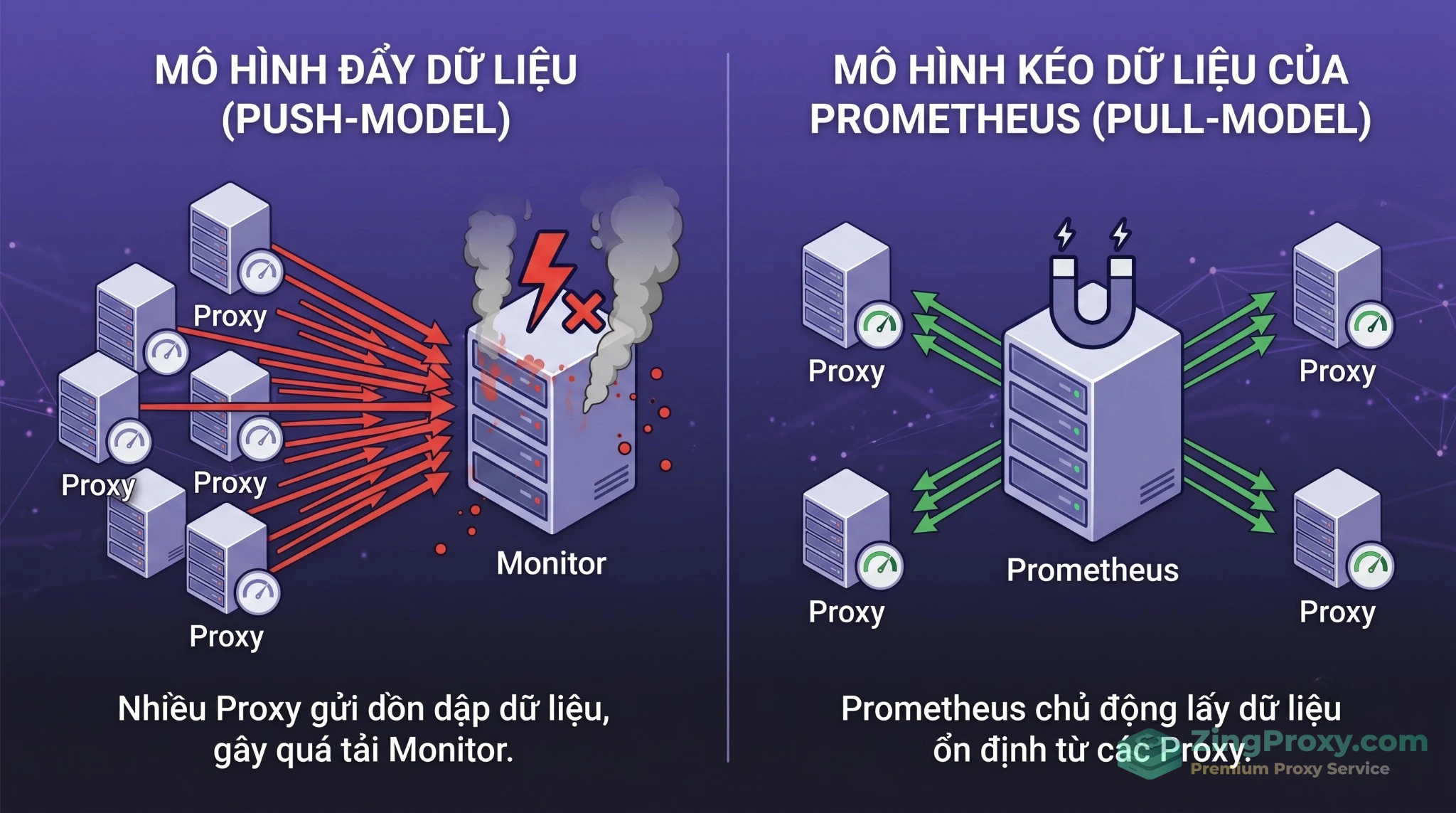
Đặc biệt, khác với mô hình Push-model (nơi các proxy tự đẩy lượng log khổng lồ về làm quá tải server monitor), Prometheus sử dụng cơ chế Pull-model. Máy chủ giám sát sẽ chủ động scrape (thu thập) dữ liệu từ các proxy node theo chu kỳ.
Nhờ Pull-model, nếu mạng chập chờn, dữ liệu trên node vẫn được bảo toàn dưới dạng bộ đếm (counter). Hơn nữa, Prometheus tích hợp sẵn Service Discovery, giúp nó tự động nhận diện Proxy node mới ngay khi khởi tạo, xóa bỏ hoàn toàn gánh nặng phải cấu hình IP thủ công cho hàng trăm node.
Khác biệt cốt lõi: Cơ chế Pull-model giúp hệ thống giám sát Prometheus hoàn toàn làm chủ lưu lượng, tránh bị quá tải ngược khi các proxy node tăng tải.
Kiến trúc tiêu chuẩn của một hệ thống giám sát Proxy Grafana
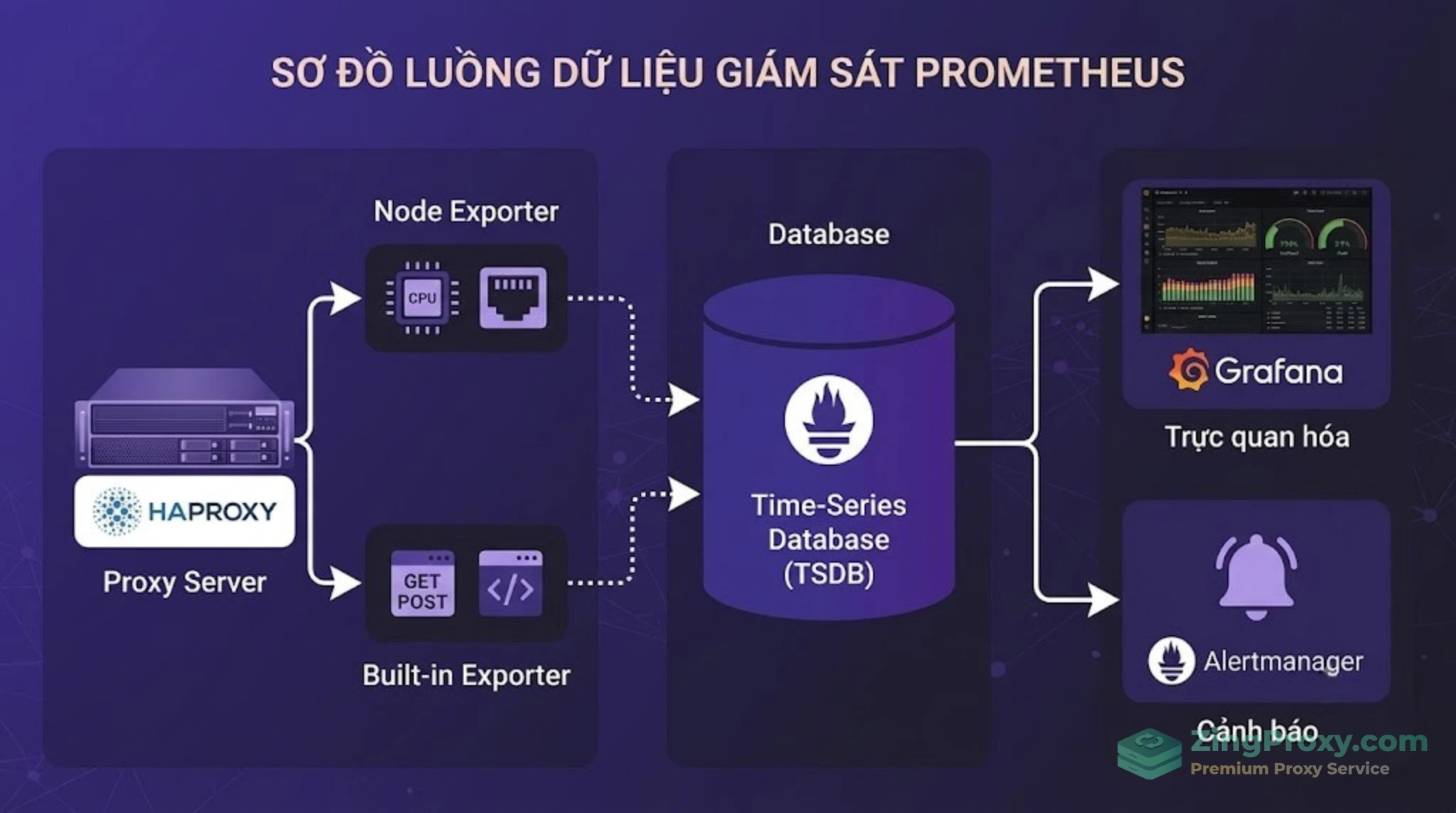
Một hệ thống Enterprise cần phân tách rõ ràng lớp thu thập dữ liệu để không bỏ sót bất kỳ điểm mù nào trên cả mô hình OSI.
Lớp thu thập (Exporters): Phân định rõ Hardware và Application
Sự nhầm lẫn lớn nhất của các developer khi setup monitor là chỉ dùng một exporter duy nhất. Thực tế, bạn cần hai thành phần để quan sát toàn diện:
Node Exporter (Tầng L1/L2/L3/L4): Đo lường thông lượng trực tiếp tại giao diện mạng vật lý (NIC). Nhóm metric node_network_* sẽ cho bạn biết chính xác tổng số byte in/out, tình trạng rớt gói (packet drop) do tràn bộ đệm hay cạn kiệt tài nguyên CPU/RAM hệ điều hành.
Proxy-specific Exporter (Tầng L7): Thay vì nhìn gói tin thô, exporter này phân tích request HTTP. Nó đo lường tổng request, tốc độ phản hồi backend, và bóc tách rõ ràng bao nhiêu mã lỗi 200, 404, hay 502 đang trả về cho client.
Tại sao HAProxy lại là lựa chọn tối ưu cho môi trường Enterprise?
Mặc dù cả Nginx và HAProxy khi so sánh đều có những thế mạnh riêng, nhưng HAProxy lại được lòng cộng đồng Sysadmin trong mảng monitor hơn cả. Lý do là từ phiên bản 2.0 trở lên, HAProxy đã tích hợp sẵn Prometheus exporter built-in. Bạn không cần cài thêm bất kỳ script hay tool bên thứ ba nào, giảm thiểu tối đa rủi ro bảo mật và độ trễ khi xử lý dữ liệu.
Kiến trúc Observability tiêu chuẩn: Dữ liệu được bóc tách rành mạch từ tầng phần cứng (Node Exporter) đến tầng ứng dụng (HAProxy), lưu trữ qua TSDB và hiển thị realtime trên Grafana.
Hướng dẫn step-by-step: Triển khai nhanh bằng Docker Compose
Dưới đây là hướng dẫn triển khai stack Prometheus và Grafana đảm bảo tính lưu trữ bền vững và bảo mật cao nhất.
Bước 1: Dựng stack Prometheus & Grafana với docker-compose.yml
Trước tiên, việc phân quyền thư mục là cực kỳ quan trọng để tránh lỗi permission-denied khiến container crash-loop liên tục. Grafana sử dụng User ID (UID) là 472, còn Prometheus dùng UID 65534 (nobody).
Lưu ý thực chiến: Việc chung network monitoring giúp Grafana gọi Prometheus qua hostname nội bộ http://prometheus:9090, ẩn hoàn toàn port của Prometheus khỏi mạng public.
Bước 2: Kích hoạt Endpoint Metrics trên HAProxy
Mở file /etc/haproxy/haproxy.cfg của bạn và thêm block sau để cấu hình native exporter:
Khởi động lại HAProxy. Giờ đây toàn bộ metrics đã sẵn sàng được thu thập tại port 8404.
Bước 3: Cấu hình prometheus.yml để scrape target
Tạo file prometheus.yml nằm cùng cấp với thư mục compose:
global:
scrape_interval: 15s # Chu kỳ kéo dữ liệu tiêu chuẩn cho real-time
scrape_configs:
- job_name: 'haproxy_nodes'
static_configs:
- targets: ['192.168.1.10:8404'] # Thay bằng IP HAProxy của bạn
labels:
group: 'production'
- job_name: 'node_exporter'
static_configs:
- targets: ['192.168.1.10:9100'] # IP cài đặt Node Exporter
Dùng cờ --web.enable-lifecycle đã setup ở phần Compose, bạn có thể tải lại cấu hình Prometheus lập tức mà không cần restart lại toàn bộ container bằng lệnh sau:
curl -X POST http://localhost:9090/-/reload
Bước 4: Add Data Source và import Dashboard
Truy cập Grafana (port 3000), vào Connections > Data sources > Add data source.
Chọn Prometheus, điền URL là http://prometheus:9090 và nhấn Save & test.
Vào mục Import dashboard, bạn chỉ cần gõ ID 1860 (Node Exporter Full) để theo dõi hạ tầng phần cứng, và ID 367 (HAProxy Servers) để theo dõi luồng request ứng dụng. Mọi biểu đồ sẽ tự động hiện ra một cách kỳ diệu.
Bắt mạch server với 4 nhóm PromQL Queries cốt lõi
Dashboard template rất tiện, nhưng một Sysadmin thực thụ phải nắm được linh hồn của hệ thống giám sát Proxy Grafana: ngôn ngữ truy vấn PromQL.
Giám sát Inbound/Outbound Bandwidth (Mbps)
Băng thông thô trả về từ Node Exporter tính bằng byte. Để vẽ biểu đồ Megabits per second (Mbps) chuẩn quốc tế giống như thông số VPS của nhà mạng, chúng ta dùng công thức sau cho chiều Inbound (Tải xuống):
Sự khác biệt của irate: Hàm irate(...[1m]) tính toán tốc độ gia tăng tức thời dựa trên 2 điểm dữ liệu gần nhất trong cửa sổ 1 phút. Khác với rate (chỉ tính trung bình cộng toàn chu kỳ và làm phẳng biểu đồ), irate giúp đồ thị có độ phản hồi cực cao, cho phép bạn bắt chính xác các đợt micro-bursts (bùng nổ traffic chớp nhoáng) mà không bị che lấp.
Bộ lọc {device!~"lo|veth.*|docker.*"}: Sử dụng biểu thức chính quy (regex) để loại trừ các interface mạng ảo (docker0) hay localhost (lo), đảm bảo số liệu tính toán chỉ phản ánh đúng card mạng vật lý.
Nhân 8 để chuyển Byte sang bit, và chia 1e6 (1 triệu) để quy đổi thành Mbps.
Theo dõi Active Connections & Request Per Second (RPS)
Với hệ thống Proxy, việc kiểm soát xem các server backend có đang bị quá tải request hay không thể hiện rõ nhất qua chỉ số RPS.
irate(haproxy_frontend_http_requests_total[1m])
Phân tích Error Rates (tỉ lệ lỗi)
Một spike traffic đi kèm với sự bùng nổ của các mã lỗi Proxy 5xx hoặc lỗi kết nối mạng là dấu hiệu rõ nhất của việc server backend đã quá tải hoặc dịch vụ phía sau đang gặp sự cố:
sum by (status) (irate(haproxy_frontend_http_responses_total{status=~"5.."}[1m]))
Mở rộng: Truy vết chi tiết với Loki & Grafana Alloy
Prometheus cho bạn biết khi nào server bị nghẽn mạng và bao nhiêu băng thông bị tiêu thụ, nhưng không cho biết ai là thủ phạm.
Trong môi trường Enterprise, hãy cân nhắc tích hợp thêm Grafana Loki và Grafana Alloy (hoặc Promtail). Grafana Alloy là công cụ thu thập telemetry thế hệ mới đạt chuẩn OpenTelemetry. Alloy sẽ trực tiếp đọc các file access.log của HAProxy, xử lý metadata và đẩy về hệ thống Loki. Từ đó, bạn có thể query trực tiếp các Top Clients IP hoặc Top Domains đang ăn băng thông ngay trên cùng một màn hình Dashboard Grafana.
Alerting & Enterprise Hardening (bảo mật & scale)
Giám sát thụ động là chưa đủ. Một hệ thống vận hành trơn tru cần tự động phát cảnh báo trước khi downtime thực sự xảy ra.
Thiết lập Alert Rules: Báo động trước khi server ngừng hoạt động
Trong Prometheus, việc set rule cảnh báo quá nhạy sẽ sinh ra cảnh báo sai (false positive) do các đợt tăng tải chớp nhoáng, gây nhiễu và khiến team vận hành dễ bỏ qua cảnh báo. Hãy dùng cờ for: 5m để yêu cầu điều kiện bất thường phải diễn ra liên tục 5 phút.
Ví dụ Rule cảnh báo khi băng thông Inbound vượt ngưỡng 80% capacity của card mạng vật lý:
groups:
- name: resource_utilization_alerts
rules:
- alert: HostUnusualNetworkThroughputIn
expr: ((irate(node_network_receive_bytes_total[5m]) / node_network_speed_bytes) > 0.80) and node_network_speed_bytes > 0
for: 5m
labels:
severity: warning
annotations:
summary: "Băng thông tải xuống quá cao trên {{ $labels.instance }}"
description: "Giao diện {{ $labels.device }} đang sử dụng hơn 80% capacity liên tục trong 5 phút."
Kết hợp với Alertmanager, các cảnh báo này sẽ lập tức được bắn webhook về Slack, Telegram hoặc hệ thống PagerDuty của team trực chiến.
Đừng đợi đến khi khách hàng gọi điện phàn nàn: Hệ thống Alertmanager sẽ chủ động “thổi còi” qua Telegram hoặc Slack ngay khi tài nguyên server chạm ngưỡng nguy hiểm.
Tối ưu lưu trữ dữ liệu dài hạn (Retention Policy)
Một sai lầm chí mạng khiến server monitor ngừng hoạt động là để ổ cứng bị đầy (Disk Full) do lưu time-series data quá lâu. Đối với môi trường lớn, phương pháp thực hành tốt nhất là:
Lưu trữ cục bộ siêu ngắn: Chỉ set --storage.tsdb.retention.time=15d hoặc thậm chí 2h trong file config của Prometheus để RAM và Disk I/O luôn ở trạng thái rảnh rỗi.
Đẩy dữ liệu ra Remote Storage: Sử dụng các hệ thống lưu trữ phân tán thế hệ mới như Thanos hoặc Grafana Mimir (phiên bản thay thế mạnh mẽ, hiệu năng cao cho Cortex đã ngừng phát triển) để offload dữ liệu dài hạn (hàng tháng, hàng năm) lên Amazon S3 (Object Storage). Nhờ đó, bạn có thể thực hiện capacity planning mượt mà, truy xuất lịch sử xa mà không lo quá tải server giám sát.
Câu hỏi thường gặp (FAQ)
1. Nên dùng Push-model hay Pull-model để giám sát hệ thống?
Hãy dùng Pull-model (như Prometheus). Máy chủ giám sát sẽ chủ động kéo dữ liệu, giúp tránh tình trạng bị các proxy node tấn công (DDoS ngược), không lo mất dữ liệu đệm khi mạng chập chờn và dễ scale hàng loạt nhờ Service Discovery.
2. HAProxy có hỗ trợ Prometheus không?
Có. Từ phiên bản 2.0 trở đi, HAProxy đã tích hợp sẵn module prometheus-exporter (built-in). Bạn chỉ cần thêm 1 dòng cấu hình http-request use-service prometheus-exporter là xuất được metric ngay, không cần cài tool hãng thứ ba.
3. Hạ tầng của tôi đang dùng HAProxy phiên bản cũ (v1.8), liệu có tích hợp được không?
Được nhưng tốn công. Bản cũ không có exporter tích hợp sẵn. Bạn phải chạy thêm một tiến trình độc lập là haproxy_exporter của cộng đồng. Khuyến nghị nâng cấp lên các bản LTS mới (v3.x) để tối ưu hiệu năng.
4. Tôi chỉ cài HAProxy Exporter và bỏ qua Node Exporter thì có sao không?
Không nên. Bạn sẽ bị thiếu tầm nhìn hạ tầng. HAProxy Exporter chỉ đo tầng ứng dụng (request, lỗi 5xx). Nếu server mất kết nối do tràn RAM, full CPU hay rớt gói vật lý ở tầng L1-L4, bạn sẽ hoàn toàn không biết nguyên nhân nếu thiếu Node Exporter.
5. Tại sao biểu đồ băng thông trên Grafana của tôi lại báo số thấp hơn thực tế và đồ thị không hiển thị các đỉnh tải?
Do bạn dùng sai hàm rate() (chuyên tính trung bình cộng, làm phẳng đỉnh). Hãy đổi ngay sang hàm irate() – tính tốc độ gia tăng tức thời để bắt chính xác các đợt micro-bursts (bùng nổ traffic chớp nhoáng).
6. Prometheus ngốn quá nhiều ổ cứng (Disk Full) khiến server ngừng hoạt động liên tục, xử lý thế nào?
Set lại cờ lưu trữ cục bộ cực ngắn: --storage.tsdb.retention.time=2d (giữ 2 ngày). Để lưu dài hạn chuẩn Enterprise, hãy đẩy dữ liệu sang các nền tảng Remote Storage như Grafana Mimir hoặc Thanos lưu trên Amazon S3.
7. Cảnh báo Alert báo nghẽn mạng, nhưng tôi check CPU/RAM vẫn ở mức rất thấp (<30%). Tại sao?
Lỗi không nằm ở CPU/RAM. Có 2 nguyên nhân: Bạn đã chạm ngưỡng băng thông tối đa (Bandwidth Cap) do nhà cung cấp VPS giới hạn, hoặc server bị cạn kiệt cổng kết nối TCP (Port Exhaustion). Hãy tune lại thông số sysctl.
Kết luận
Việc xây dựng một hệ thống giám sát Proxy Grafana chuẩn Enterprise không chỉ là bài toán về cài đặt phần mềm, mà là nghệ thuật tối ưu hóa tài nguyên và chủ động kiểm soát rủi ro. Với combo Prometheus, Grafana và sự linh hoạt của HAProxy, bạn đã nắm trong tay một radar toàn cảnh, sẵn sàng đón đầu và triệt tiêu mọi bất thường về luồng dữ liệu trước khi chúng kịp gây hại đến hệ thống.
2 giờ sáng, hệ thống giám sát ping báo lỗi hàng loạt, màn hình hiển thị 502 Bad Gateway. Traffic spike chạm đỉnh, băng thông nghẽn cứng, proxy server từ chối mọi request. Trong lúc dầu sôi lửa bỏng, anh em Sysadmin vẫn phải hì hục SSH vào từng node, gõ lệnh tail -f đọc […]
Bạn đã bao giờ nhìn thấy pipeline GitHub Actions xanh rờn, test local pass 100%, hí hửng deploy lên Production rồi ngay lập tức nhận ticket report lỗi khẩn cấp từ user ở Nhật Bản vì trang thanh toán hiển thị USD thay vì JPY chưa? Hoặc một user ở Đức phàn nàn rằng họ […]
Đang thu thập dữ liệu mượt mà, pipeline chạy trơn tru, đột nhiên console đỏ rực một dải log: HTTP 429 Too Many Requests. Dữ liệu gãy nhịp, worker kẹt cứng, và tệ nhất là địa chỉ IP server chính thức mất kết nối. Đây chắc hẳn là kịch bản ám ảnh mà bất kỳ […]
Nhìn vào màn hình console với chỉ số CPU chạm nóc 100%, RAM cạn kiệt và MySQL liên tục báo lỗi Too many connections là cơn ác mộng kinh điển của bất kỳ developer hay sysadmin nào. Khi một bài viết trên WordPress bất ngờ viral hoặc hệ thống chạy chiến dịch quảng cáo lớn, […]
Tám giờ tối, bạn vừa deploy xong một tính năng cực mượt có tích hợp AI. Nhưng khi lượng user bắt đầu tăng lên, log trên backend liên tục báo lỗi với những dòng chữ đỏ: ECONNRESET, ETIMEDOUT, hoặc các luồng Server-Sent Events (SSE) đang stream dở văn bản thì đột ngột bị ngắt kết […]
Bạn vừa gõ xong lệnh git push, pipeline CI/CD kích hoạt. Đáng lý ra chỉ khoảng 10 phút sau là team sẽ nhận được report review code và test case sinh tự động từ AI. Nhưng thực tế lại tàn nhẫn hơn nhiều: Cả team ngồi nhìn màn hình terminal tĩnh lặng ròng rã 40 […]