














































































































































Official ZingProxy
01/07/2023
Cách thu thập dữ liệu an toàn từ Wayback Machine
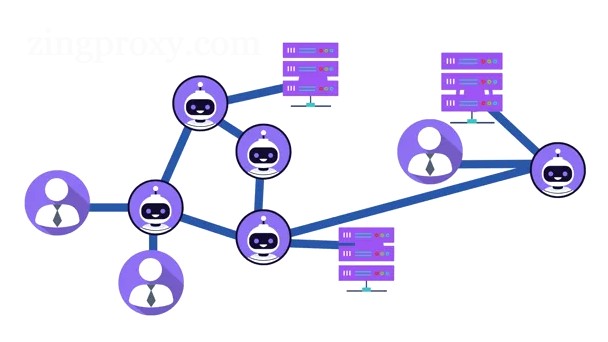
Bạn đang tìm cách thu thập dữ liệu từ Wayback Machine? Wayback Machine sẽ giúp bạn bạn có được tất cả dữ liệu của mình ở một nơi mà không phải xử lý các trang web khác nhau. Bất kể quy mô dữ liệu bạn muốn thu thập, sử dụng công cụ này sẽ giúp bạn đạt được điều đó trong vài phút, thậm chí bao gồm hàng trăm hoặc hàng nghìn trang web. Nhờ công nghệ, nó giúp bạn tránh được căng thẳng, kém hiệu quả, sai sót và lãng phí thời gian khi thu thập dữ liệu thủ công. Trong blog này, chúng tôi sẽ chỉ cho bạn cách thu thập dữ liệu một cách an toàn và hiệu quả từ Wayback Machine.