Mặc dù đã qua một thời gian, nhưng ChatGPT vẫn cho thấy sức nóng của nó trong mọi lĩnh vực. Cơ bản ChatGPT là một AI (trí tuệ nhân tạo) giúp bạn tạo các cuộc trò chuyện tự động và trả lời các câu hỏi về nhiều chủ đề và lĩnh vực khác nhau. Tìm hiểu cách sử dụng ChatGPT để tự động hóa hoàn toàn việc web scraping. Đi sâu vào sức mạnh của AI và khai thác dữ liệu quan trọng từ web theo cách thân thiện với người dùng. Hãy cùng bắt đầu!
ChatGPT là mô hình ngôn ngữ lớn được phát triển bởi OpenAI. Nó được thiết kế để tạo ra văn bản giống con người dựa trên một đầu vào nhất định và đã tìm thấy nhiều ứng dụng trên nhiều lĩnh vực. Trong trường hợp của chúng tôi, chúng tôi sẽ sử dụng ChatGPT để tự động hóa quy trình web scraping.
Giải thích về quá trình web scraping
Web scraping hay quét web là quá trình tự động trích xuất dữ liệu từ các trang web. Dữ liệu này sau đó có thể được sử dụng cho nhiều mục đích khác nhau như phân tích dữ liệu, học máy (ML) hoặc nghiên cứu thị trường. Theo truyền thống, việc quét web bao gồm việc viết một tập lệnh, thường bằng Python, để tìm nạp một trang web và trích xuất dữ liệu cần thiết. Ngoài ra việc thu thập dữ liệu còn được kết hợp phổ biến với proxy, được gọi chung là dịch vụ proxy webscraping.
Bắt đầu với ChatGPT
Các bước đăng ký tài khoản ChatGPT trên website OpenAI
Để bắt đầu sử dụng ChatGPT để web scraping, trước tiên bạn cần tạo một tài khoản trên trang web của OpenAI. OpenAI cung cấp cấp độ miễn phí cho ChatGPT, cho phép bạn thử nghiệm và xem trực tiếp khả năng của mô hình. Nếu bạn đã có tài khoản, chỉ cần đăng nhập để bắt đầu.
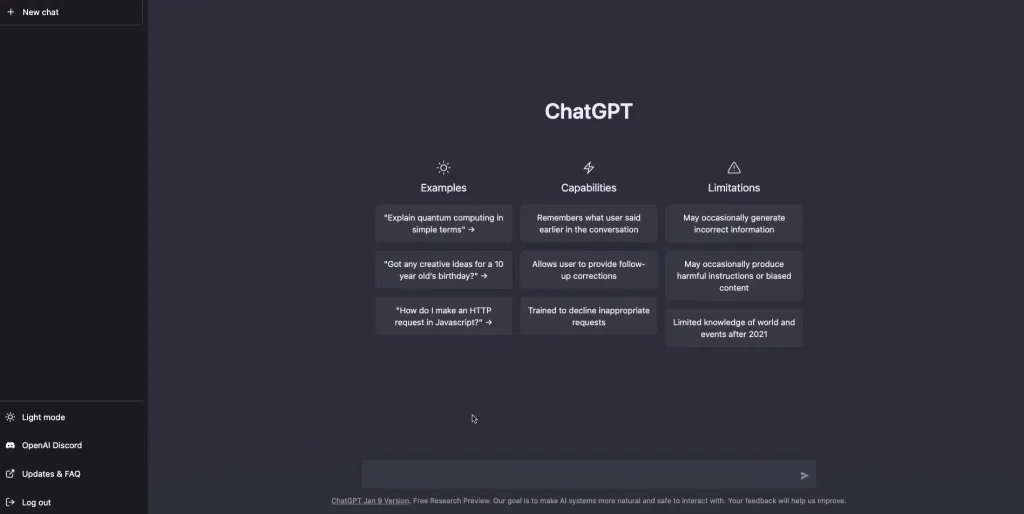
Hiểu giao diện người dùng ChatGPT
Sau khi đăng nhập vào tài khoản OpenAI, bạn sẽ thấy giao diện người dùng ChatGPT. Tại đây, bạn có thể bắt đầu cuộc trò chuyện mới với AI. Giao diện hội thoại rất dễ sử dụng, bạn nhập lời nhắc hoặc lệnh và ChatGPT sẽ tạo phản hồi.
Giao diện chính của ChatGPT
Chuẩn bị cho ChatGPT để tự động hóa hoàn toàn việc web scraping
Chọn một trang web để thu thập dữ liệu từ đó
Trước khi có thể tự động hóa quy trình web scraping, bạn cần phải quyết định trang web nào bạn muốn trích xuất dữ liệu từ đó. Đây có thể là bất kỳ trang web nào bạn muốn. Ví dụ: bạn có thể muốn trích xuất dữ liệu phim từ IMDb hoặc danh sách sản phẩm từ trang web thương mại điện tử.
Quyết định loại dữ liệu nào sẽ được trích xuất từ trang web đã chọn
Ngoài việc chọn trang web, bạn cũng cần chỉ định loại dữ liệu bạn muốn trích xuất. Đây có thể là những thông tin cụ thể như tiêu đề, năm phát hành và xếp hạng của một bộ phim trên IMDb hoặc tên, giá và thông số kỹ thuật của sản phẩm trên trang thương mại điện tử,…
Tự động thực hiện Web scraping bằng ChatGPT
Cách nhập cuộc trò chuyện mới trong ChatGPT bằng hướng dẫn web scraping
Sau khi quyết định chọn trang web và dữ liệu cần trích xuất, bạn có thể nhập cuộc trò chuyện mới trong ChatGPT để tạo mã web scraping. Một hướng dẫn có thể trông giống như sau: “Web Scrape [URL] with Python and Beautiful Soup”. URL phải được thay thế bằng trang web bạn muốn thu thập.
Ví dụ về hướng dẫn web scraping cho một trang web cụ thể
Ví dụ: nếu bạn muốn quét trang IMDb Top 250, hướng dẫn của bạn đối với ChatGPT sẽ là: “Web Scrape https://www.imdb.com/chart/top/ with Python and Beautiful Soup”. Sau khi nhấn return, ChatGPT sẽ tạo tập lệnh Python cần thiết.
Giải thích về tập lệnh Python được tạo và mã Beautiful Soup
Tập lệnh do ChatGPT tạo sẽ bao gồm mã Python sử dụng thư viện yêu cầu để tìm nạp trang web và thư viện Beautiful Soup để trích xuất dữ liệu mong muốn. Sau đó, mã này có thể được sao chép từ giao diện ChatGPT và chạy trong môi trường Python cục bộ của bạn để thực hiện quy trình quét web.
Các bước để cài đặt các thư viện Python cần thiết cho việc web scraping
Trước khi có thể chạy tập lệnh đã tạo, điều quan trọng là phải đảm bảo rằng các thư viện Python cần thiết đã được cài đặt trong môi trường của bạn. Cụ thể, chúng ta sẽ cần các thư viện request và beautifulsoup4. Bạn có thể cài đặt các thư viện này bằng pip, trình cài đặt gói cho Python. Mở một thiết bị đầu cuối và nhập các lệnh sau: pip install beautifulsoup4 request
Cách chạy mã được tạo trong môi trường Python
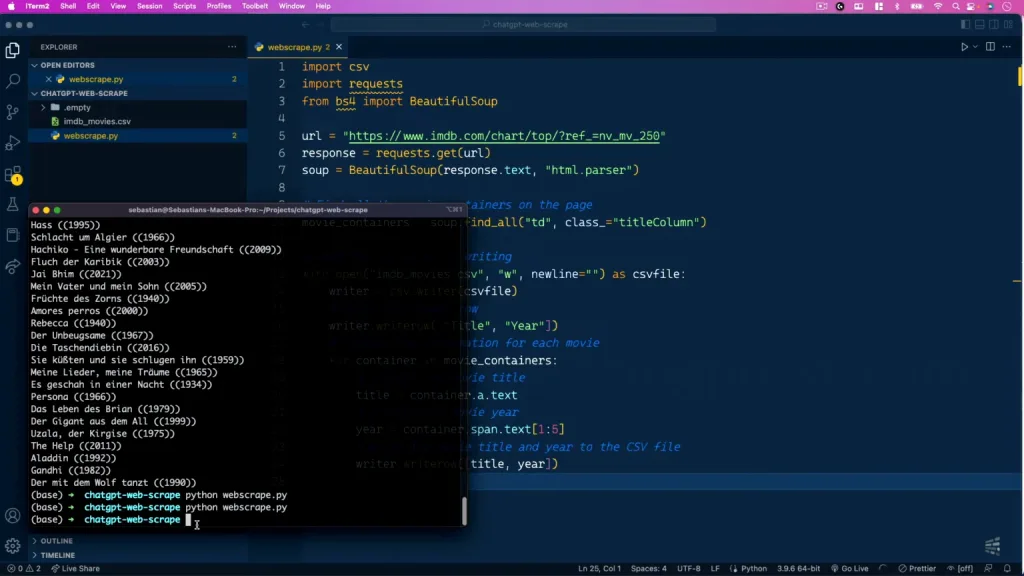
Sau khi cài đặt các thư viện cần thiết, bạn đã sẵn sàng chạy tập lệnh Python mà ChatGPT đã tạo. Sao chép tập lệnh từ giao diện ChatGPT và dán tập lệnh vào tệp Python trong trình chỉnh sửa mã ưa thích của bạn. Ví dụ: chúng ta có thể đặt tên tệp webscrape.py. Để chạy tập lệnh, hãy điều hướng đến thư mục chứa tệp Python của bạn trong terminal và thực hiện lệnh sau: python webscrape.py
Sao chép tập lệnh từ giao diện ChatGPT và dán để chạy mã trong Python
Kiểm tra mã Web scraping
Cách sao chép mã từ giao diện ChatGPT và dán vào tệp Python
Sao chép mã được tạo từ giao diện ChatGPT rất đơn giản. Sau khi ChatGPT tạo tập lệnh, nhấp vào đầu ra để chọn tập lệnh, sau đó nhấp chuột phải và chọn ‘Copy‘. Trong trình chỉnh sửa mã của bạn, hãy mở tệp Python mới, nhấp chuột phải và chọn ‘Paste‘ để chèn mã.
Chạy mã được tạo và xác thực đầu ra
Khi chạy tập lệnh webscrape.py của bạn, bảng điều khiển sẽ xuất dữ liệu đã được thu thập từ trang web được chỉ định. Đảm bảo kiểm tra chéo kết quả đầu ra với dữ liệu thực tế trên trang web để xác thực tính chính xác và đầy đủ của nó.
Tinh chỉnh và tùy chỉnh mã Web scraping bằng ChatGPT
Sửa đổi tập lệnh được tạo theo nhu cầu cụ thể
Tùy thuộc vào nhu cầu dữ liệu cụ thể của bạn, bạn có thể muốn tinh chỉnh tập lệnh Python được tạo. Điều này có thể bao gồm thu hẹp dữ liệu được trích xuất hoặc thay đổi định dạng đầu ra. ChatGPT khá linh hoạt trong vấn đề này. Ví dụ: nếu ban đầu bạn yêu cầu tập lệnh trích xuất tất cả dữ liệu từ một trang nhưng bây giờ chỉ muốn thông tin cụ thể, bạn có thể hướng dẫn ChatGPT tương ứng.
Ví dụ về cách yêu cầu ChatGPT tinh chỉnh tập lệnh
Giả sử bạn chỉ muốn trích xuất tiêu đề phim và năm phát hành từ trang IMDb Top 250 và lưu dữ liệu vào tệp CSV. Bạn có thể hướng dẫn ChatGPT như sau: “Vui lòng viết lại tập lệnh này để chỉ trích xuất tiêu đề và năm từ trang IMDb Top 250 và xuất kết quả thành tệp CSV.” ChatGPT sau đó sẽ tạo tập lệnh mới tuân thủ các yêu cầu này.
Chạy tập lệnh đã sửa đổi và xem lại kết quả
Sau khi bạn có tập lệnh đã tinh chỉnh, hãy thay thế tập lệnh trước đó trong tệp Python bằng tập lệnh mới. Chạy lại bằng phương pháp tương tự như trước. Nếu tập lệnh chính xác, nó sẽ tạo ra tệp CSV chỉ chứa tên phim và năm phát hành.
Kết quả hiển thị sau khi đã sửa đổi tập lệnh
Cách sử dụng nâng cao ChatGPT để thực hiện Web scraping
Khám phá các tính năng và chức năng bổ sung của ChatGPT để Web scraping
Ngoài những điều cơ bản, còn có những cách nâng cao hơn để sử dụng ChatGPT cho việc quét web. Ví dụ: bạn có thể hướng dẫn mô hình tạo tập lệnh điều hướng nhiều trang của trang web hoặc xử lý các phiên đăng nhập cho các trang web yêu cầu xác thực. Khả năng của ChatGPT rất phong phú và đáng để khám phá những tính năng này để tối đa hóa hiệu quả của các tác vụ quét web của bạn.
Mẹo và phương pháp hay nhất để quét web scraping hiệu quả bằng ChatGPT
Để tận dụng tối đa việc sử dụng ChatGPT cho web scraping, dưới đây là một số mẹo:
Hãy rõ ràng và cụ thể trong hướng dẫn của bạn về ChatGPT. Mô hình hoạt động tốt nhất khi được cung cấp chi tiết chính xác về dữ liệu được trích xuất.
Kiểm tra kỹ mã được tạo của bạn. Điều quan trọng là phải đảm bảo tính chính xác của dữ liệu đã được thu thập của bạn.
Sử dụng khả năng tinh chỉnh của ChatGPT. Nếu tập lệnh ban đầu không đáp ứng yêu cầu của bạn, bạn luôn có thể hướng dẫn mô hình sửa lại nó.
Khám phá các tính năng nâng cao của ChatGPT. Mô hình này có khả năng làm được nhiều việc hơn là chỉ tạo các tập lệnh thu thập dữ liệu cơ bản. Vì vậy đừng ngần ngại thử các hướng dẫn phức tạp hơn.
Ưu điểm và nhược điểm của việc Web scraping với ChatGPT
Ưu điểm:
Tạo mã: Một trong những lợi thế chính của việc sử dụng ChatGPT để quét web là khả năng tạo mã Python. Thay vì phải viết các tập lệnh Scrap phức tạp theo cách thủ công, bạn có thể hướng dẫn ChatGPT tạo mã, tiết kiệm đáng kể thời gian và công sức.
Tính linh hoạt và tùy chỉnh: ChatGPT rất linh hoạt và có thể được tùy chỉnh dựa trên yêu cầu của người dùng. Bạn có thể hướng dẫn nó sửa đổi tập lệnh được tạo nếu bạn muốn thay đổi dữ liệu cần trích xuất hoặc định dạng của đầu ra.
Khả năng nâng cao: ChatGPT cung cấp các khả năng nâng cao, như tạo tập lệnh có thể điều hướng nhiều trang hoặc xử lý các phiên đăng nhập. Điều này làm cho nó trở thành một công cụ mạnh mẽ cho các tác vụ quét web có độ phức tạp khác nhau.
Nhược điểm:
Sự phụ thuộc vào thư viện của bên thứ ba: Các tập lệnh do ChatGPT tạo phụ thuộc vào thư viện Python của bên thứ ba như BeautifulSoup và Requests. Điều này có nghĩa là bạn cần đảm bảo các thư viện này được cài đặt và cập nhật trong môi trường Python của mình, điều này có thể là trở ngại đối với một số người dùng.
Kiểm soát hạn chế đối với mã: Mặc dù ChatGPT tạo mã hiệu quả nhưng người dùng có quyền kiểm soát hạn chế đối với các cấu trúc và chức năng mã cụ thể được sử dụng. Điều này có thể gây bất lợi cho người dùng muốn thực hiện các chiến lược hoặc phương pháp mã hóa cụ thể.
Độ chính xác của mã được tạo: Độ chính xác và hiệu quả của mã được tạo phụ thuộc vào độ rõ ràng và cụ thể của các hướng dẫn được cung cấp cho ChatGPT. Điều này có nghĩa là người dùng cần phải hướng dẫn rất rõ ràng và rõ ràng. Do đó nó có thể là thách thức đối với những người mới làm quen với việc quét web.
Vậy là với những chia sẻ ở trên về việc sử dụng ChatGPT cho Web scraping, chúng ta hẳn đã có cái nhìn tổng quát về những điều thú vị cũng như cách sử dụng kết hợp chúng để đạt được hiệu quả tối ưu nhất, giúp hiện thực hóa mục tiêu và rút gọn quy trình thu thập dữ liệu cần thiết của bạn. Liên hệ với chúng tôi qua zingproxy.com để được giải quyết nhanh nhất những câu hỏi của bạn!
Hệ thống vừa chạy chiến dịch marketing, traffic đổ về ầm ầm. Ứng dụng phình to và bạn bắt đầu nhận được những tin nhắn cảnh báo đỏ rực trên Slack: CPU của máy chủ Database đang chạm nóc 100%. Các lỗi Too many connections hoặc 502/504 Gateway Timeout xuất hiện dày đặc, dẫn đến […]
Nếu bạn đang đọc bài viết này, rất có thể bạn vừa gõ lệnh yum update trên máy chủ VPS production và nhận về hàng loạt thông báo lỗi 404. CentOS 7 đã chính thức ngừng hỗ trợ vào ngày 30/06/2024, và CentOS 8 cũng đã ngừng hoạt động từ cuối năm 2021. Hệ thống […]
Đang chạy luồng data pipeline ổn định để thu thập dữ liệu giá sản phẩm thì log báo lỗi liên tục với mã 403 Forbidden và 429 Too Many Requests. API bị rate-limit, IP server bị block cứng, hoặc hệ thống trả về toàn dữ liệu lỗi do cơ chế bảo vệ của máy chủ […]
Bạn vừa thuê một chiếc VPS Linux mới, hoàn tất cài đặt Ubuntu, mở port 22 cho SSH, deploy ứng dụng và an tâm rằng hệ thống đã an toàn? Hãy mở terminal lên và chạy ngay dòng lệnh kiểm tra log này: Con số trả về có thể khiến bạn giật mình: hàng trăm, […]
Bạn đang ngồi tại văn phòng Agency, nhấn nút chạy tool rank tracker trên server, mỉm cười hài lòng khi thấy hàng loạt từ khóa của khách hàng chễm chệ trên Top 1 Google Maps. Bạn tự tin xuất report PDF và gửi đi. Nhưng chỉ 15 phút sau, khách hàng gọi lại từ một […]
Đã bao nhiêu lần bạn phải thức dậy lúc 2 giờ sáng chỉ vì một node Minecraft bị crash, rò rỉ RAM (memory leak) rồi kéo sập toàn bộ các server khác đang chạy chung trên máy chủ? Việc quản lý hàng tá game server qua giao diện dòng lệnh (CLI) truyền thống, gõ những […]