Các doanh nghiệp thu thập dữ liệu Facebook để thực hiện phân tích đối thủ cạnh tranh. Việc thu thập dữ liệu có thể trở nên cồng kềnh nếu không có công cụ và kiến thức phù hợp. Trong hướng dẫn này, chúng tôi sẽ chia sẻ cách thu thập dữ liệu Facebook (Facebook Scraping) một cách hợp pháp, những công cụ nào cần thiết để có tỷ lệ thành công cao và cách tránh lệnh cấm địa chỉ IP. Ngoài ra, chúng tôi sẽ cung cấp ví dụ thực tế về việc quét các trang Facebook bằng Python và Selenium.
Facebook scraping là một cách tự động thu thập dữ liệu từ nền tảng Facebook. Mọi người thường thu thập dữ liệu Facebook bằng cách sử dụng các công cụ thu thập dữ liệu trên web được tạo sẵn hoặc các công cụ thu thập dữ liệu tùy chỉnh. Dữ liệu đã thu thập sau đó được phân tích cú pháp (làm sạch) và xuất thành định dạng dễ phân tích như .json. Bằng cách quét các điểm dữ liệu như bài đăng, lượt thích hoặc người theo dõi, doanh nghiệp thu thập ý kiến của khách hàng, phân tích xu hướng thị trường, theo dõi các nỗ lực xây dựng thương hiệu trực tuyến và bảo vệ danh tiếng của họ.
Facebook scraping có hợp pháp không?
Mặc dù các nền tảng truyền thông xã hội có thể không thích việc webscraping, nhưng hành động thu thập dữ liệu có sẵn công khai là hợp pháp. Tuy nhiên, điều đó không ngăn chủ sở hữu của Facebook tích cực đấu tranh chống lại bất kỳ ai lấy dữ liệu khỏi nền tảng của họ.
Dữ liệu Facebook nào bạn có thể thu thập?
Đầu tiên và quan trọng nhất, nếu bạn muốn thu thập dữ liệu mạng xã hội, bạn cần đảm bảo rằng dữ liệu đó có sẵn công khai và không được bảo vệ bởi luật bản quyền. Dưới đây là các danh mục chính có sẵn công khai trên Facebook:
Hồ sơ: bài đăng mới nhất, tên người dùng, URL hồ sơ, URL ảnh hồ sơ, lượt theo dõi và người theo dõi, lượt thích và sở thích cũng như thông tin công khai khác có trong hồ sơ.
Bài đăng: bài đăng mới nhất, ngày tháng, vị trí, lượt thích, lượt xem, bình luận, văn bản và URL phương tiện.
Hashtags: URL bài đăng, URL phương tiện, ID tác giả bài đăng.
Các trang kinh doanh trên Facebook: URL, hình ảnh hồ sơ, tên, lượt thích, câu chuyện, người theo dõi, thông tin liên hệ, trang web, danh mục, tên người dùng, hình đại diện, thông tin trang liên quan.
Nếu bạn muốn thu thập thông tin cá nhân thì sẽ phải áp dụng nhiều quy tắc hơn.
Cách chọn công cụ để thực hiện Facebook Scraping
Một cách để thực hiện việc thu thập thông tin trên Facebook là xây dựng công cụ thu thập thông tin của riêng bạn bằng cách sử dụng các khung như Selenium và Playwright. Cả hai đều là những công cụ phổ biến để kiểm soát các headless browser cần thiết để quét Facebook. Tuy nhiên, nền tảng này có tính thù địch, vì vậy một công cụ tự xây dựng là tốt nhất cho người dùng từ trung cấp đến cao cấp.
Một giải pháp dễ dàng hơn là sử dụng dụng cụ thu thập làm sẵn. Hãy lấy Facebook-page-scraper làm ví dụ. Đó là một gói Python được tạo để quét phần đầu của các trang Facebook. Những công cụ dọn dẹp như vậy đã bao gồm logic để trích xuất và cấu trúc dữ liệu liên quan. Tuy nhiên, chúng sẽ không hoạt động nếu không có các công cụ bổ sung như proxy giúp che giấu IP.
Tùy chọn đơn giản nhất là mua một công cụ quét web thương mại. Có một số tùy chọn để lựa chọn dựa trên kiến thức kỹ thuật và nhu cầu của bạn:
Nếu bạn không muốn can thiệp vào mã, hãy sử dụng công cụ quét không có mã. Các dịch vụ như Parsehub, PhantomBuster hoặc Octoparse cung cấp các công cụ cho phép bạn trích xuất dữ liệu bằng cách nhấp vào các phần tử trực quan. Chúng tiện dụng cho việc thu thập dữ liệu quy mô nhỏ hoặc khi bạn không cần chạy một thiết lập phức tạp.
Ngoài ra, bạn có thể lấy API quét web. Chúng giống với các công cụ quét web được tạo sẵn nhưng được bảo trì tốt hơn và tích hợp sẵn tất cả các yếu tố cần thiết. Vì vậy, tất cả những gì bạn cần làm là gửi yêu cầu và lưu trữ đầu ra.
Proxy là công cụ không thể thiếu để thực hiện Facebook Scraping
Cách scraping các bài đăng trên Facebook bằng Python
Trong ví dụ này, chúng tôi sẽ sử dụng trình quét dựa trênPython – Facebook-page-scraper 5.0.2. Nó có hầu hết logic quét web được viết sẵn, không giới hạn số lượng yêu cầu bạn có thể thực hiện và bạn sẽ không cần phải đăng ký hoặc có khóa API.
Công cụ cần thiết để bắt đầu Facebook Scraping
Để trình quét hoạt động, bạn sẽ cần sử dụngmáy chủ proxy và thư viện headless browser. Facebook thực hiện nhiều hành động chống lại những kẻ thu thập thông tin từ yêu cầu giới hạn khối địa chỉ IP. Một proxy có thể giúp tránh kết quả này bằng cách che giấu địa chỉ IP và vị trí của bạn. Bạn sẽ cần một headless browser vì hai lý do. Đầu tiên, nó sẽ giúp chúng ta tải các phần tử động. Và thứ hai, vì Facebook sử dụng tính năng bảo vệ chống bot, nó sẽ cho phép bạn bắt chước dấu vân tay thực tế của trình duyệt.
Trước khi bắt đầu, bạn cần có Python và thư viện JSON. Sau đó, bạn sẽ cần cài đặt Facebook-page-scraper. Bạn có thể làm điều này bằng cách gõ lệnh cài đặt pip vào thiết bị đầu cuối:
pip install facebook-page-scraper
Các thay đổi đối với Code
Bây giờ, hãy thực hiện một số thay đổi đối với các tệp thu thập.
Để tránh lời nhắc chấp thuận cookie, trước tiên bạn cần sửa đổi tệp driver_utilities.py. Nếu không, trình thu thập sẽ tiếp tục cuộn lời nhắc và bạn sẽ không nhận được bất kỳ kết quả nào.
1) Sử dụng lệnh show trong bảng điều khiển của bạn để tìm các tệp. Nó sẽ trả về thư mục lưu các tập tin.
pip show facebook_page_scraper
2) Bây giờ, trong driver_utilities.py, hãy thêm mã vào cuối định nghĩa wait_for_element_to_appear.
@staticmethod
def __wait_for_element_to_appear(driver, layout):
"""expects driver's instance, wait for posts to show.
post's CSS class name is userContentWrapper
"""
try:
if layout == "old":
# wait for page to load so posts are visible
body = driver.find_element(By.CSS_SELECTOR, "body")
for _ in range(randint(3, 5)):
body.send_keys(Keys.PAGE_DOWN)
WebDriverWait(driver, 30).until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '.userContentWrapper')))
elif layout == "new":
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[aria-posinset]")))
except WebDriverException:
# if it was not found,it means either page is not loading or it does not exists
print("No posts were found!")
Utilities.__close_driver(driver)
# exit the program, because if posts does not exists,we cannot go further
sys.exit(1)
except Exception as ex:
print("error at wait_for_element_to_appear method : {}".format(ex))
Utilities.__close_driver(driver)
allow_span = driver.find_element(
By.XPATH, '//div[contains(@aria-label, "Allow")]/../following-sibling::div')
allow_span.click()
3) Nếu định quét nhiều trang cùng lúc, bạn phải sửa đổi tài liệu scraper.py. Bản cập nhật này sẽ tách thông tin từ các mục tiêu quét khác nhau thành các tệp riêng biệt.
Di chuyển các dòng sau vào phương thức init(). Ngoài ra, hãy thêm tham số self. vào đầu các dòng đó.
__data_dict = {}
and __extracted_post = set()
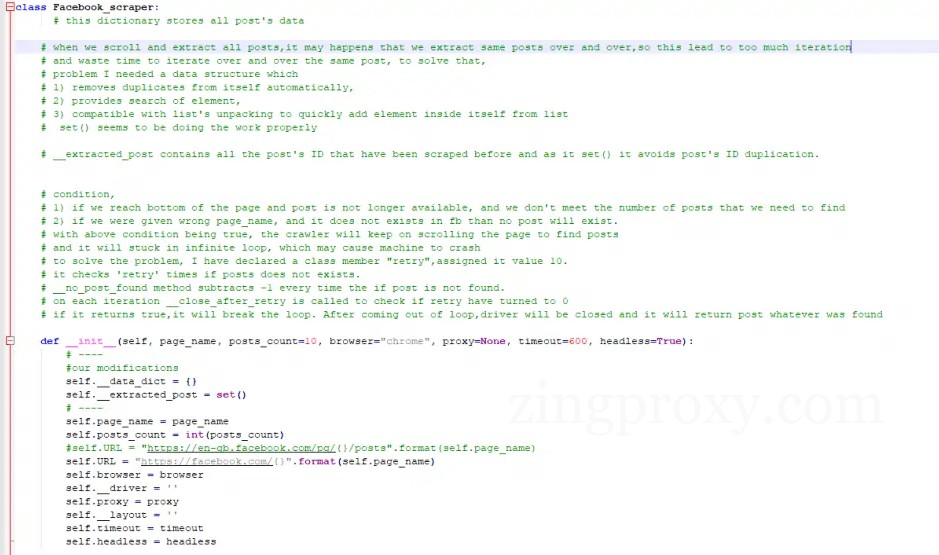
Đây là giao diện của tệp sau khi thực hiện thay đổi:
Giao diện sau khi thực hiện thay đổi quét bằng Python
Cách scraping các bài đăng trên Facebook bằng Selenium
Ví dụ này sẽ sử dụng proxy dân cư và Selenium. Với việc dùng proxy dân cư bạn sẽ có một địa chỉ như ở nhà, vì Facebook đủ thông minh để xác định và chặn IP của trung tâm dữ liệu.
Bước 1
Tạo một tệp văn bản mới trong thư mục bạn chọn và đổi tên thành facebook1.py. Sau đó, mở tài liệu và bắt đầu viết mã chính.
1) Nhập công cụ quét.
from facebook_page_scraper import Facebook_scraper
2) Sau đó, hãy chọn những trang bạn muốn quét. Ví dụ này đã chọn một số hồ sơ công khai và nhập chúng dưới dạng giá trị chuỗi. Hoặc, bạn luôn có thể quét từng trang một.
1) Tạo một biến proxy port có giá trị số. Bạn có thể sử dụng bất kỳ nhà cung cấp proxy di động hoặc proxy dân cư xoay IP nào.
proxy_port = 10001
2) Tiếp theo, viết số lượng bài đăng bạn muốn thu thập cho biến posts count.
posts_count = 100
3) Sau đó, chỉ định trình duyệt. Bạn có thể sử dụng Google Chrome hoặc Firefox.
browser = "firefox"
4) Biến timeout sẽ kết thúc quá trình quét sau một khoảng thời gian không hoạt động. Khi chỉ định nó, hãy viết thời gian tính bằng giây. 600 giây là tiêu chuẩn, nhưng bạn có thể điều chỉnh nó theo nhu cầu của mình.
timeout = 600
5) Chuyển sang biến headless browser. Nhập false dưới dạng boolean nếu bạn muốn xem hoạt động của trình thu thập. Nếu không, hãy viết true và chạy mã ở chế độ nền.
headless = False
Bước 3
Nếu nhà cung cấp proxy của bạn yêu cầu xác thực, hãy đặt mật khẩu và tên người dùng của bạn vào dòng proxy. Sau đó, ngăn cách chúng bằng dấu hai chấm.
for page in page_list:
proxy = f'username:[email protected]:{proxy_port}'
Sau đó, khởi tạo trình quét. Ở đây, tiêu đề trang, số lượng bài đăng, loại trình duyệt và các biến khác được chuyển thành đối số của hàm.
Nếu bạn muốn xuất nó thành tệp CSV, hãy tạo một thư mục có tên facebook_scrape_results hoặc bất kỳ thứ gì phù hợp với bạn, sau đó để nó làm biến thư mục.
directory = "C:\\facebook_scrape_results"
2) Sau đó, với hai dòng sau, dữ liệu từ mỗi trang Facebook sẽ được lưu trữ trong một tệp có tiêu đề tương ứng.
Cuối cùng, đối với một trong hai phương pháp, hãy thêm mã và proxy xoay IP sẽ xoay IP của bạn sau mỗi phiên. Bằng cách này, bạn sẽ an toàn trước các lệnh cấm IP.
proxy_port += 1
Lưu mã và chạy nó trong thiết bị đầu cuối của bạn. Nếu chọn phương thức trình bày đầu ra đầu tiên, kết quả sẽ hiển thị trên màn hình sau vài giây.
from facebook_page_scraper import Facebook_scraper
page_list = ['KimKardashian','arnold','joebiden','eminem','smosh','SmoshGames','ibis','Metallica','cnn']
proxy_port = 10001
posts_count = 100
browser = "firefox"
timeout = 600 #600 seconds
headless = False
# Dir for output if we scrape directly to CSV
# Make sure to create this folder
directory = "C:\\facebook_scrape_results"
for page in page_list:
#our proxy for this scrape
proxy = f'username:[email protected]:{proxy_port}'
#initializing a scraper
scraper = Facebook_scraper(page, posts_count, browser, proxy=proxy, timeout=timeout, headless=headless)
#Running the scraper in two ways:
# 1
# Scraping and printing out the result into the console window:
# json_data = scraper.scrap_to_json()
# print(json_data)
# 2
# Scraping and writing into output CSV file:
filename = page
scraper.scrap_to_csv(filename, directory)
# Rotating our proxy to the next port so we could get a new IP and avoid blocks
proxy_port += 1
Vậy là bài viết này đã chia sẻ tới các bạn cách Facebook Scraping – thu thập dữ liệu hợp pháp trên Facebook với Python, Proxy và Selenium. Đặc biệt với cách sử dụng proxy các bạn co thể hoàn toàn yên tâm về quá trình, giới hạn địa lý quét cũng như về quy mô thu thập của mình. Việc kết hợp các phương án này với nhau cũng là cách bạn có thể thử. Liên hệ qua zingproxy.com để được giả đáp những câu hỏi về proxy cũng như đăng ký dịch vụ proxy chất lượng cao tại đây. Chúc các bạn thành công!
Tra cứu mã bưu chính Việt Nam 2026 sau sáp nhập là bước nên làm trước khi gửi hàng, điền billing hoặc khai báo tài khoản. Nhiều người vẫn quen dùng địa chỉ cũ nên cùng một địa chỉ nhưng lúc nhận được hàng, lúc hệ thống lại báo sai ZIP code. Từ 2025 đến […]
Với team Marketing làm nhiều tài khoản quảng cáo, shop thương mại điện tử hoặc hệ thống khách hàng, việc nhiều người cùng đăng nhập từ các mạng khác nhau luôn là điểm rủi ro lớn. Chỉ cần IP thay đổi liên tục, thiết bị không đồng nhất hoặc phân quyền lỏng, tài khoản có […]
Trong bối cảnh hệ sinh thái quảng cáo kỹ thuật số toàn cầu ngày càng phát triển với các mô hình mua bán tự động (Programmatic Advertising) tinh vi, việc đảm bảo từng đồng ngân sách được chi trả đúng vị trí, đúng đối tượng chưa bao giờ trở nên cấp thiết đến thế. Đối […]
Trong kỷ nguyên số, khi ranh giới giữa an toàn và bị xâm nhập chỉ cách nhau vài mili-giây, các biện pháp bảo mật đơn lớp (single-layer) như VPN hay Proxy truyền thống đang dần mất đi vị thế độc tôn trước các hệ thống giám sát và phân tích lưu lượng bằng AI. Đối […]
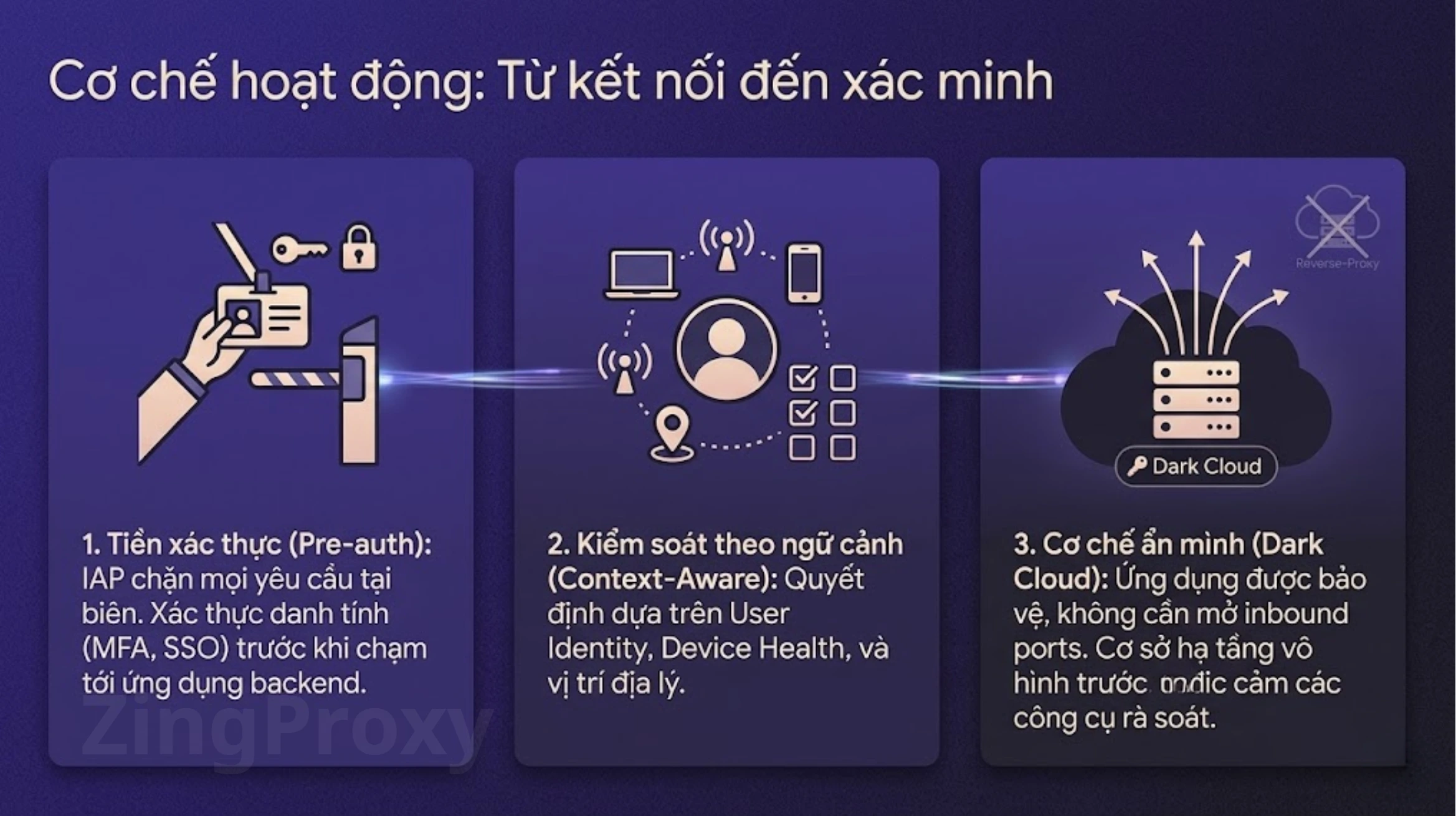
Trong hơn hai thập kỷ, an ninh mạng doanh nghiệp vận hành dựa trên tư duy “Lâu đài và Hào nước” (Castle-and-Moat). Chiến lược này giả định rằng vành đai mạng là ranh giới tuyệt đối: mọi thứ bên ngoài là nguy hiểm, còn mọi thứ bên trong mạng nội bộ (LAN) là đáng tin […]
Trong kỷ nguyên Big Data, dữ liệu được ví như dầu mỏ của nền kinh tế số. Tuy nhiên, khả năng khai thác nguồn tài nguyên này một cách ổn định, liên tục và trên quy mô lớn mới chính là lợi thế cạnh tranh thực sự của doanh nghiệp. Các Data Engineer thường xuyên […]